5.3MAP
and ML Receivers for Symbol-by-Symbol Decisions
This section discusses two decision criteria widely adopted in communication receivers:
maximum a posteriori (MAP) and maximum likelihood (ML). Under some conditions,
MAP and ML can be the optimum data detection strategy for minimizing
. For
example, for the AWGN channel, MAP executed in a symbol-by-symbol basis (in this case
the channel is memoryless) is the optimum criterion. When the symbols are uniformly
distributed, ML is equivalent to MAP and, consequently, ML is optimum for AWGN with
uniform symbol priors.
The discussion assumes the receiver knows all
conditional
PDFs
and they are the correct ones. MAP and ML also guide the receiver in the situation where a
decision must be done of a sequence of symbols. But here, for simplicity, only
symbol-by-symbol decisions are discussed.
When using the ML criterion, the receiver defines the decision regions by choosing:
ML =
Hence, after observing a given value ,
all values for
the symbols ,
,
are calculated and the chosen symbol is the one that achieves the maximum
.
Note that, commonly, the elements of
are continuous random variables. For example, for AWGN,
is distributed according
to a Gaussian. Hence,
is not a probability but a likelihood (in the context of this text, the value of a continuous PDF or the
PDF itself). This is the reason for the name ML criterion. ML does not take into account the prior
probabilities ,
which can be important, as illustrated by the example in Figure 5.4.
The distinction with respect to ML is that MAP takes the priors in account and is the
optimum solution in the general case of non-uniform priors.
The MAP criterion seeks the maximization of the posteriori distribution
:
MAP =
The posteriors
can be obtained via the Bayes’ theorem as in Eq. (A.62), repeated here for convenience:
Because
is the same normalization factor for all candidates
,
Eq. (5.3) is equivalent to
MAP =
Eq. (5.3) should be compared to Eq. (5.1). It is possible to prove that the decision regions
imposed by the MAP criterion are optimal according to the following reasoning, which assumes
is a discrete r. v.
for simplicity.2
For each received , if
there is only one symbol
for which ,
then and
does not contribute
to . If there are two
or more symbols for
which , then the decision
will surely influence .
In order to see that, assume the symbols for which
are
and
. Choosing
would imply adding
the parcels to
(see Eq. (5.1)), while
choosing would imply
adding the parcels .
Therefore, choosing
is the optimal decision because it minimizes the parcel that contributes to
.
As mentioned, when the symbols are uniformly distributed, i. e., all priors
are the same, the ML and MAP criteria lead to the same result. For AWGN, all
are Gaussians with the same variance (imposed by the noise) and the symmetry
derived from uniform priors reflects in having thresholds that are the same for
ML and MAP and in the middle point between neighbor symbols. Figure 5.5
provides an example, where the ML thresholds are relatively easy to obtain as
by
observation when the likelihood PDFs cross each other.
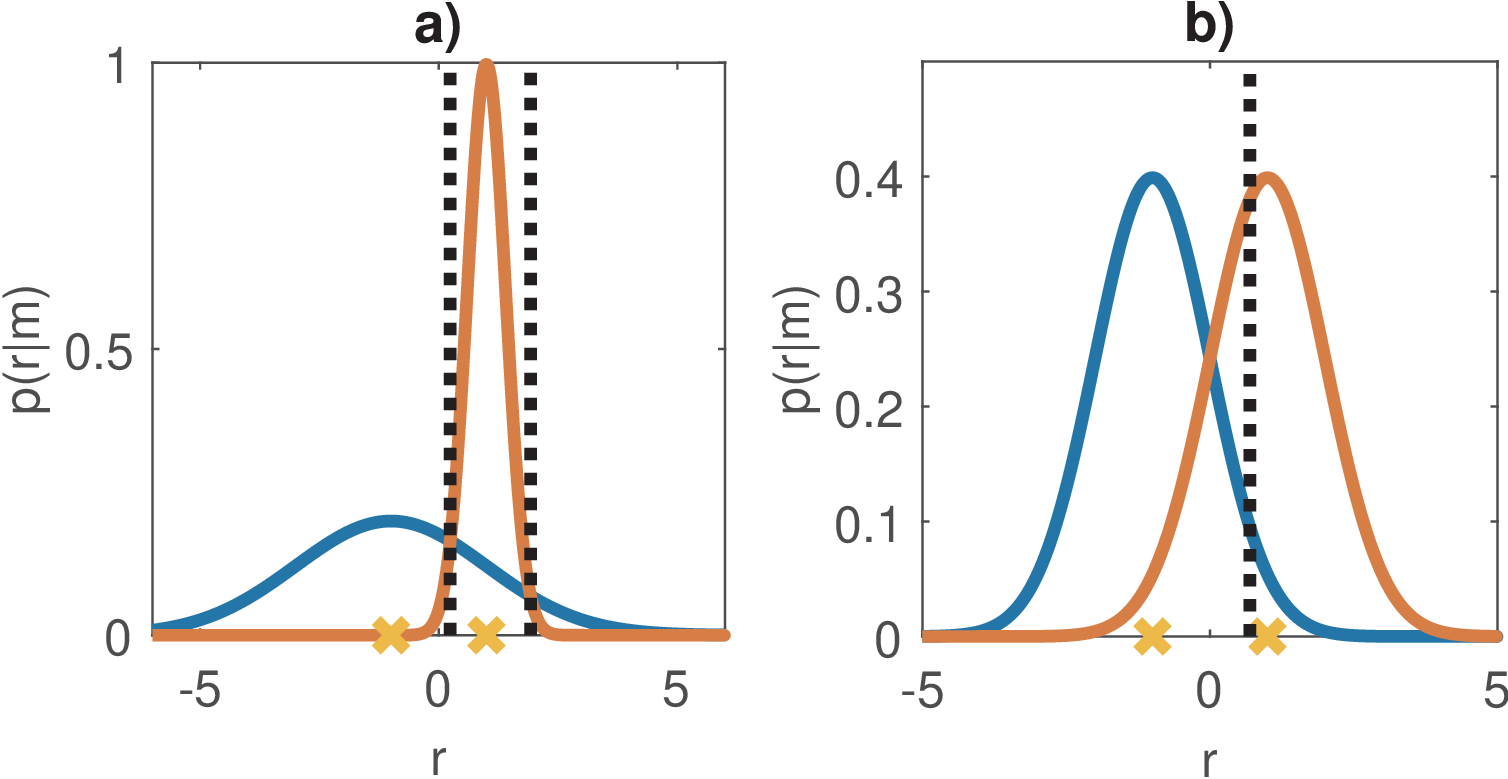
Figure 5.6: Conditional probabilities
and MAP thresholds. In case a) the priors are uniform but the variances of the
noises added to each symbol differ while in b) the variances are the same (as in
AWGN) but the priors differ.
To get insight, a more general case is assumed in the sequel. Assume binary modulation with
symbols
and ,
where
and with
. The goal is to
calculate the values of
for which
because they correspond to the threshold of the MAP decision regions:
This is a second order equation
and the two thresholds are ,
where ,
and
.
Figure 5.6 was generated with the code ak_MAPforTwoGaussians.m that implements this
calculation. In case a), the priors are uniform but the variances (2 and 0.4) are distinct and
,
, as if the noise
had distinctly affected the two symbols. Then, there are two thresholds of interest, which is always
the case when .
The MAP optimal thresholds are 0.24 and 1.93, which coincide with the ML thresholds. A receiver
that uses these two thresholds to make its decisions would achieve the Bayes error (the minimum
), which in this case is
. In case b), the variances
are the same such that
and ,
but the threshold is not in the middle point because the priors
,
differ. In this case,
because has larger
prior probability ,
the MAP optimal threshold is 0.69 and is biased in favor of the symbol
.
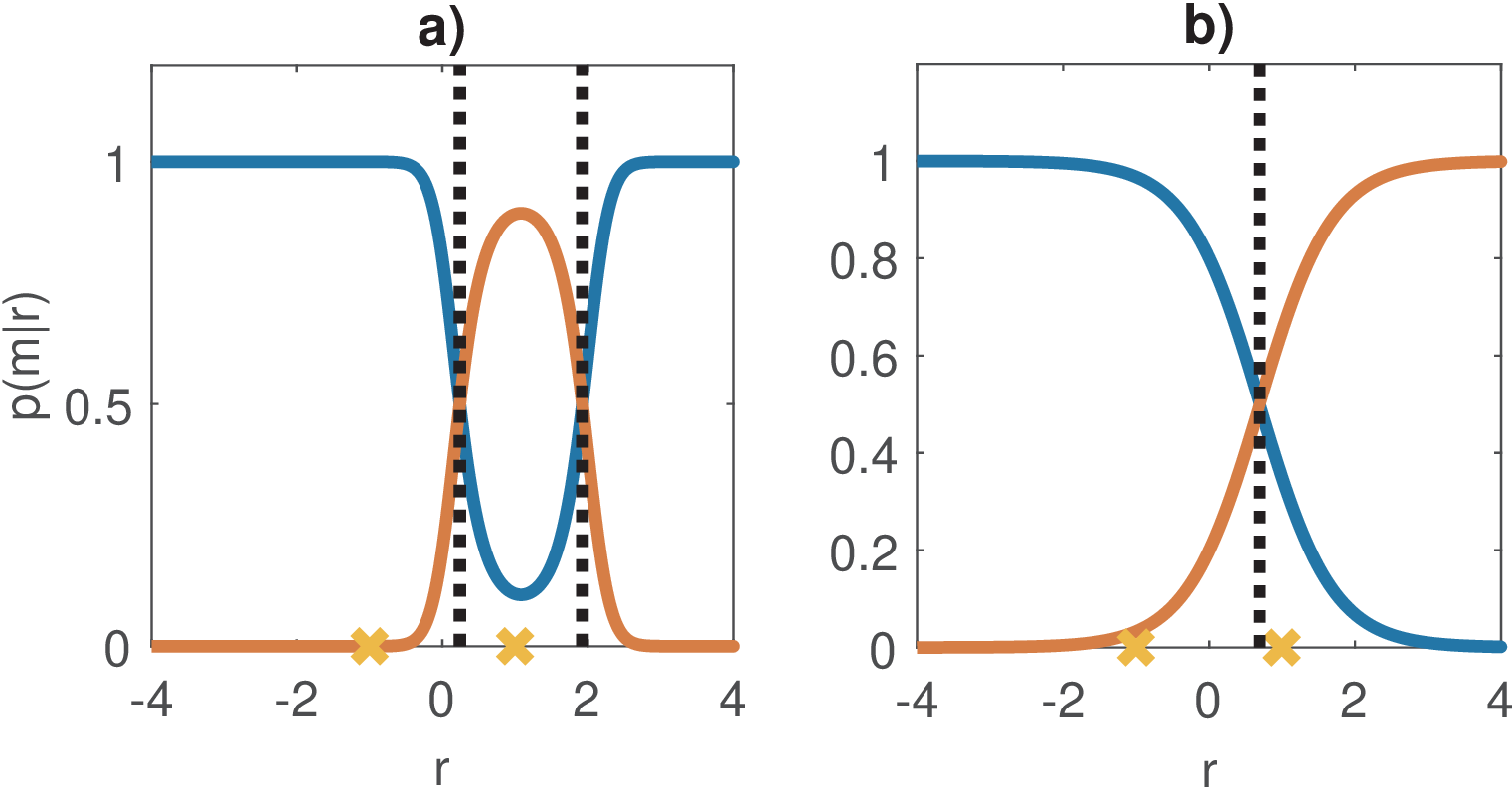
Figure 5.7: Posteriori distributions
for the examples in Figure 5.6. Note that while
are likelihoods,
are probabilities and sum up to one.
Figure 5.7 shows the posteriori distributions
for
the examples in Figure 5.6. While the MAP threshold for case b) in Figure 5.6 cannot
be found visually, it is very easy to note that 0.69 is the optimal threshold via
Figure 5.7.
It should be noted that for AWGN, because the Gaussian distribution is such that the
distance to the mean is inversely proportion to the probability, the thresholds obtained for
the ML criterion coincide with the threshold of Voronoi regions defined by the Euclidean
distances among the symbols.
2It is also assumed that ,otherwise the effective number of symbols would be less than.