B.4 Stochastic Processes
This appendix will provide a very brief overview of stochastic (or random) processes. If the reader finds extra time, he/she can find many good textbooks about them.
Stochastic or random processes are a powerful formalism for studying signals that incorporate some randomness. While the outcome of a random variable is a number, the outcome of a stochastic process is a time-series, each one called a realization. Hence, when using stochastic processes, it is possible to calculate “time” statistics of a single realization. Besides, one can choose a given time instant and calculate “ensemble” statistics over all realizations at that specific time. These two options may be confusing at first, but are essential. To get intuition on them, the reader is invited to observe the following simple example.
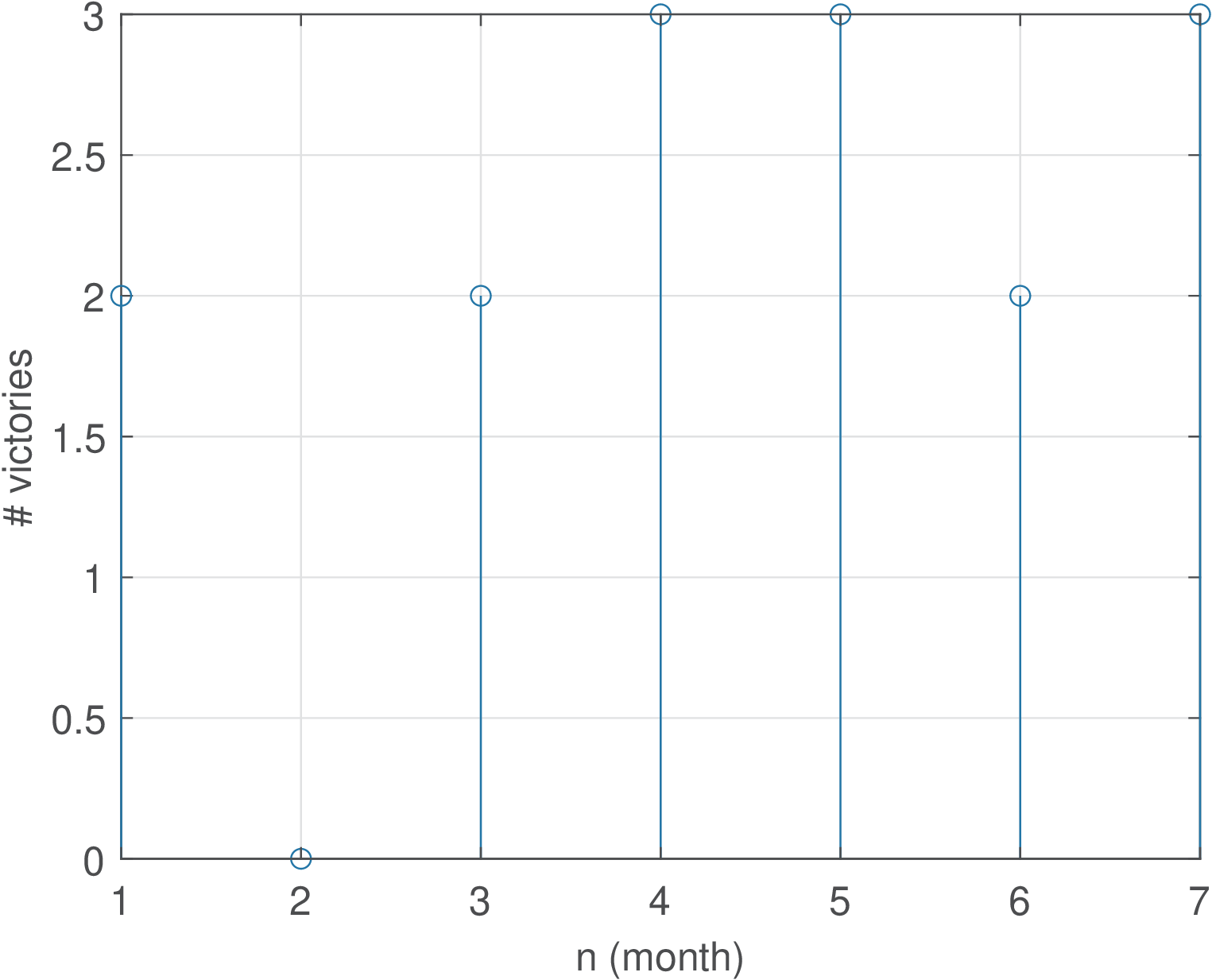
Example B.3. Simple example to explain time and ensemble averages in a stochastic process. Assume a vector [2, 0, 2, 3, 3, 2, 3] where each element represents the outcome of a random variable indicating the number of victories of a football team in four matches (one per week), along a seven-months season (for example, the team won 2 games in the first month and none in the second). One can calculate the average number of victories as , the standard deviation and other moments of a random variable. This vector could be modeled as a finite-duration random signal , with Figure B.3 depicting its graph.
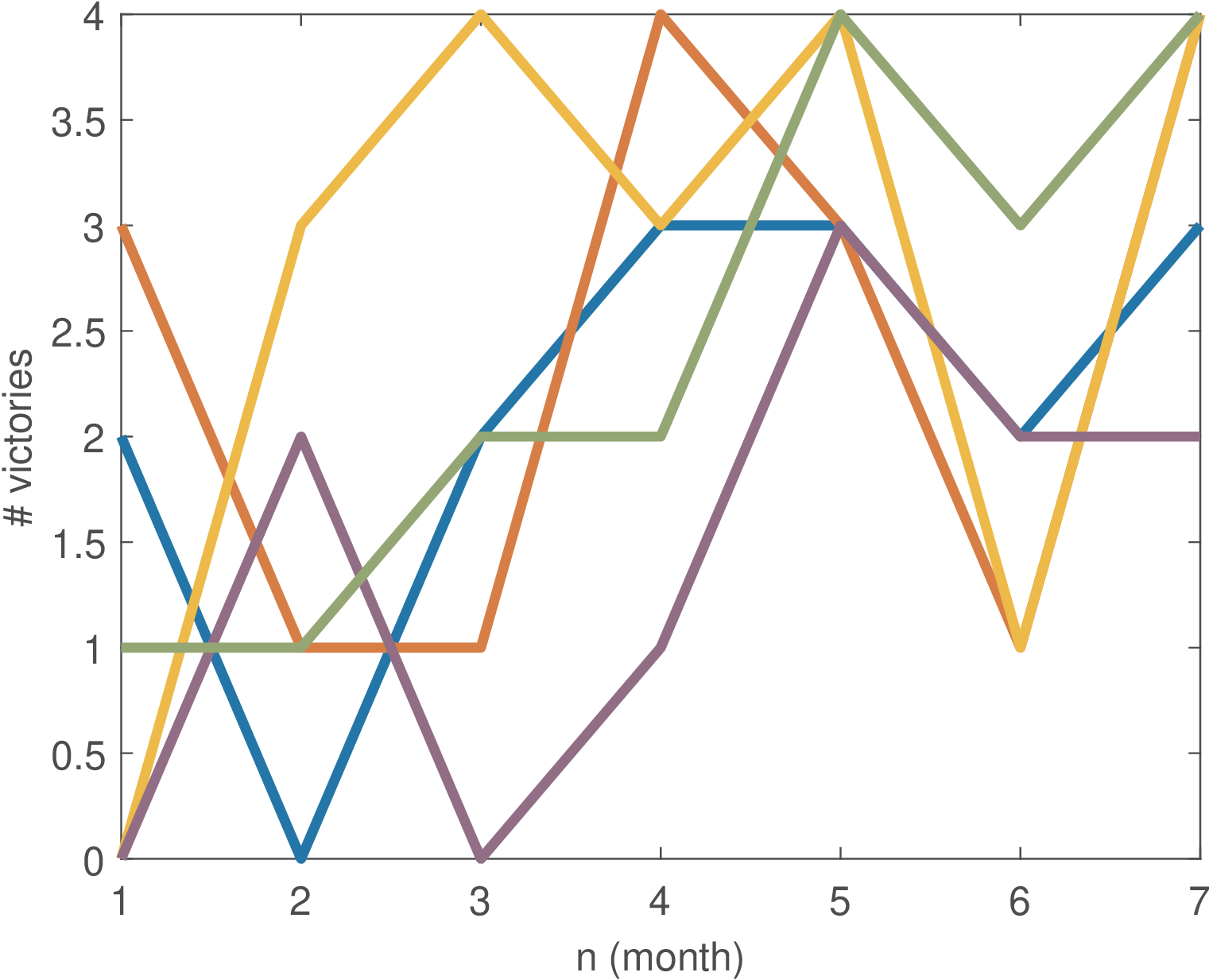
Assume now there are 5 vectors, one for each year. A discrete-time random process can be used to model the data, with each vector (a time series) corresponding to a realization of the random process. For example, following the Matlab convention of organizing different time series in columns (instead of rows), the tabular data below represents the five random signals:
victories = [ 2 3 0 0 1 0 1 3 2 1 2 1 4 0 2 3 4 3 1 2 3 3 4 3 4 2 1 1 2 3 3 4 4 2 4]
Each random signal (column) can be modeled as a realization of a random process. Figure B.4 shows a graphical representation of the data with the five realizations of the example. One should keep in mind that a random process is a model for generating an infinite number of realizations but only 5 are used here for simplicity.
A discrete-time random process will be denoted by and one of its realization as . For the sake of explaining this example, let us define the notation to indicate the -th realization of . Because is a random signal, one can calculate for the given example, and other statistics taken over time. But a random process is a richer model than a random signal and other statistics can be calculated or, equivalently, more questions can be asked.
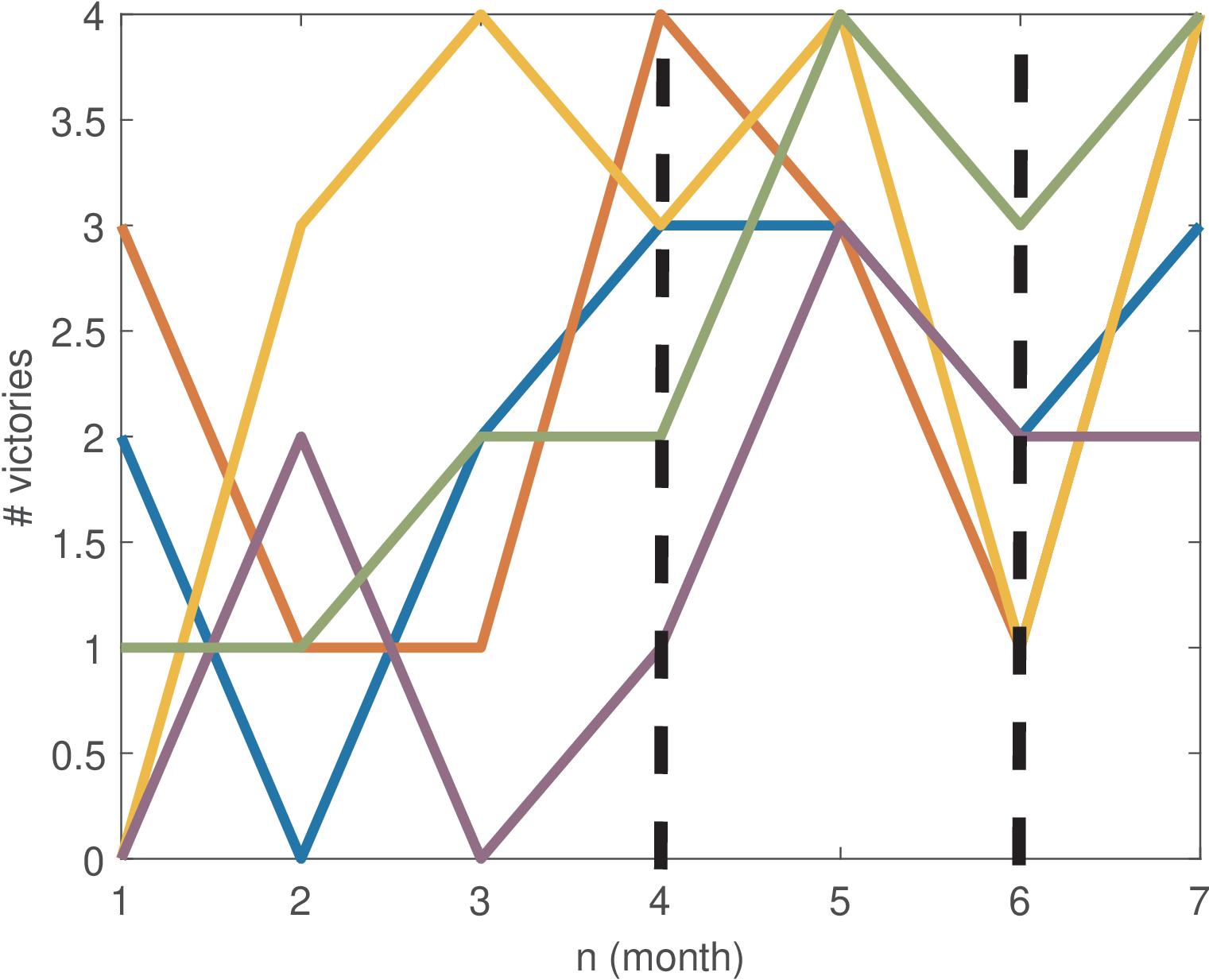
Besides asking for statistics of one realization taken over “time”, it is important to understand that when fixing a given time instant , the values that the realizations assume are also outcomes of a random variable that can be denoted by . In the example, assuming (i.e., assume the fourth month), one can estimate the average . Similarly, . Figure B.5 graphically illustrates the operation of evaluating a random process at these two time instants. Differently than the previous time averages, these “ensemble” statistics are obtained across realizations with fixed time instants.
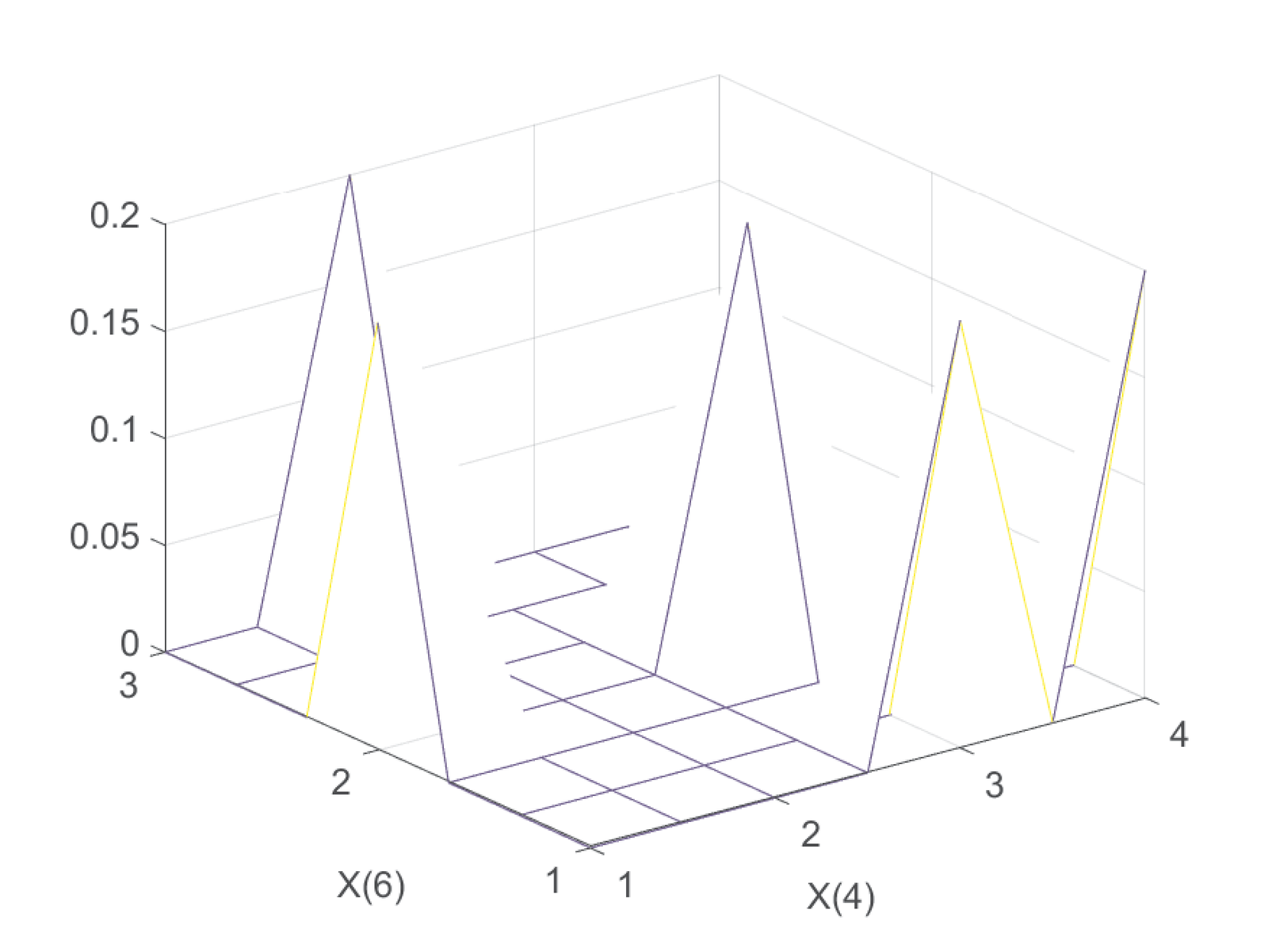
The continuous-time random process is similar to its discrete-time counterpart. Taking two different time values and leads to a pair of random variables, which can then be fully (statistically) characterized by a joint pdf function . This can be extended to three or more time instants (random variables). Back to the discrete-time example, one can use a normalized two-dimensional histogram to estimate the joint PMF of and as illustrated in Figure B.6.
This example aimed at distinguishing time and ensemble averages, which is fundamental to understand stochastic processes.
Correlation Function and Matrix
Second-order moments of a random process involve statistics taken at two distinct time instants. Two of them are the correlation and covariance functions, which are very useful in practice.
As discussed in Section 1.10, the correlation function is an extension of the correlation concept to random signals generated by stochastic processes. The autocorrelation function (ACF)
|
| (B.31) |
is the correlation between random variables and at two different points and in time of the same random process. Its purpose is to determine the strength of relationship between the values of the signal occurring at two different time instants. For simplicity, it is called instead of .
A discrete-time version of Eq. (B.31) is
|
| (B.32) |
where and are two “time” instants.
Specially for discrete-time processes, it is useful to organize autocorrelation values in the form of an autocorrelation matrix.
Example B.4. Calculating and visualizing the autocorrelation matrix (not assuming stationarity). Stationarity is a concept that will be discussed in the sequel (Appendix B.4.0.0). Calculating and visualizing autocorrelation is simpler when the process is stationary. But in this example, this property is not assumed and the autocorrelation is obtained for a general process.
Listing B.1 illustrates the estimation of for a general discrete-time random process.3
1function [Rxx,n1,n2]=ak_correlationEnsemble(X, maxTime) 2% function [Rxx,n1,n2]=ak_correlationEnsemble(X, maxTime) 3%Estimate correlation for non-stationary random processes using 4%ensemble averages (does not assume ergodicity). 5%Inputs: - X, matrix representing discrete-time process realizations 6% Each column is a realization of X. 7% - maxTime, maximum time instant starting from n=1, which 8% corresponds to first row X(1,:). Default: number of rows. 9%Outputs: - Rxx is maxTime x maxtime and Rxx[n1,n2]=E[X[n1] X*[n2]] 10% - n1,n2, lags to properly plot the axes. The values of 11% n1,n2 are varied from 1 to maxTime. 12[numSamples,numRealizations] = size(X); %get number of rows and col. 13if nargin==1 14 maxTime = numSamples; %assume maximum possible value 15end 16Rxx = zeros(maxTime,maxTime); %pre-allocate space 17for n1=1:maxTime 18 for n2=1:maxTime %calculate ensemble averages 19 Rxx(n1,n2)=mean(X(n1,:).*conj(X(n2,:))); %ensemble statistics 20 %that depends on numRealizations stored in X 21 end 22end
Figure B.7 was created with the command ak_correlationEnsemble(victories) and shows the estimated correlation for the data in Figure B.4 of Example B.3. The data cursor indicates that because for the random variables of the five realizations are . In this case, . Similar calculation leads to because in this case the products victories(1,:).*victories(7,:) are [6, 12, 0, 0, 4], which have an average of 4.4.
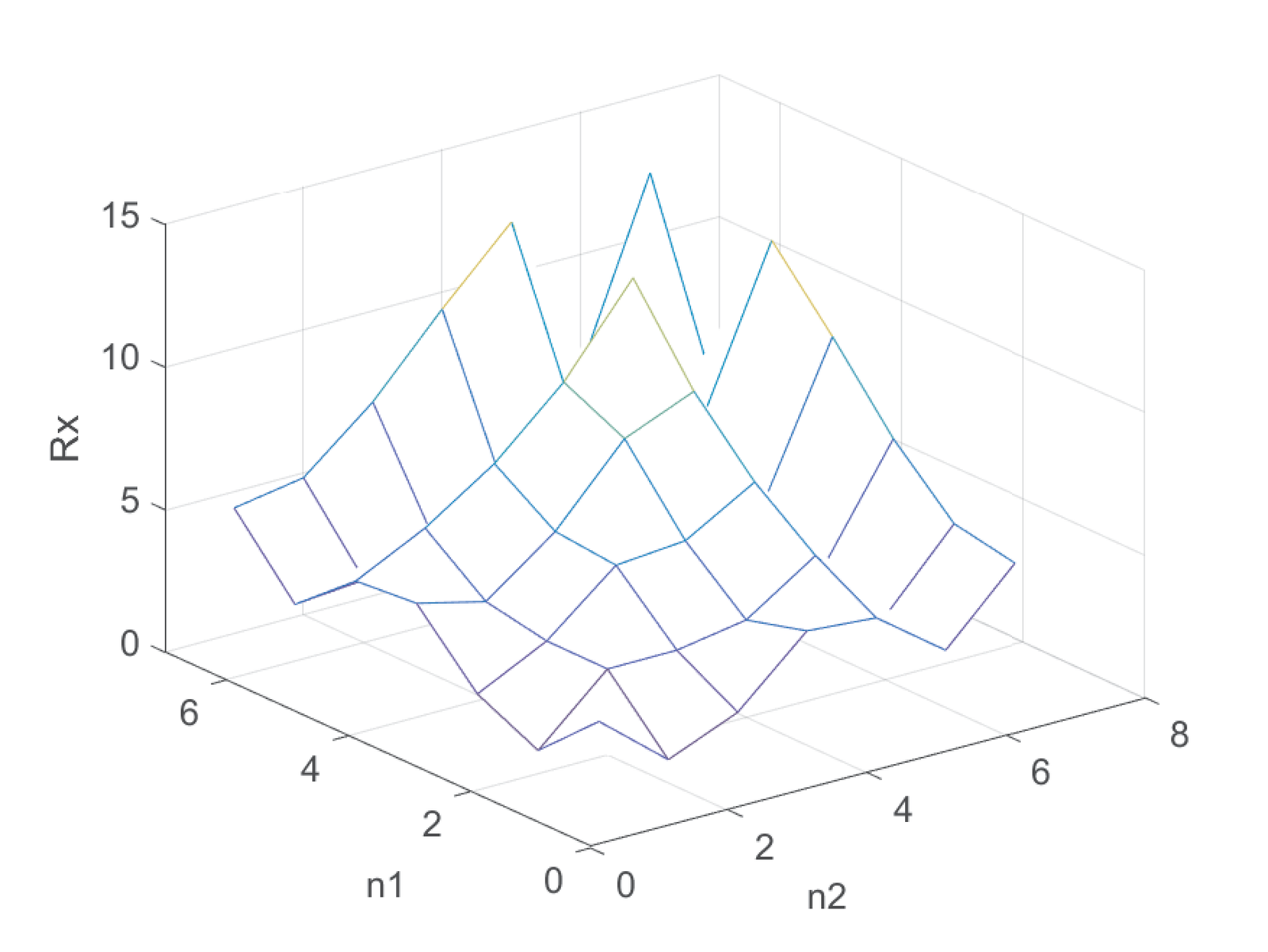
Figure B.8 presents an alternative view of Figure B.7, where the values of the z-axis are indicated in color. The two datatips indicate that and (these are the values identified by Index for the adopted colormap, and the associated color is also shown via its RGB triple).
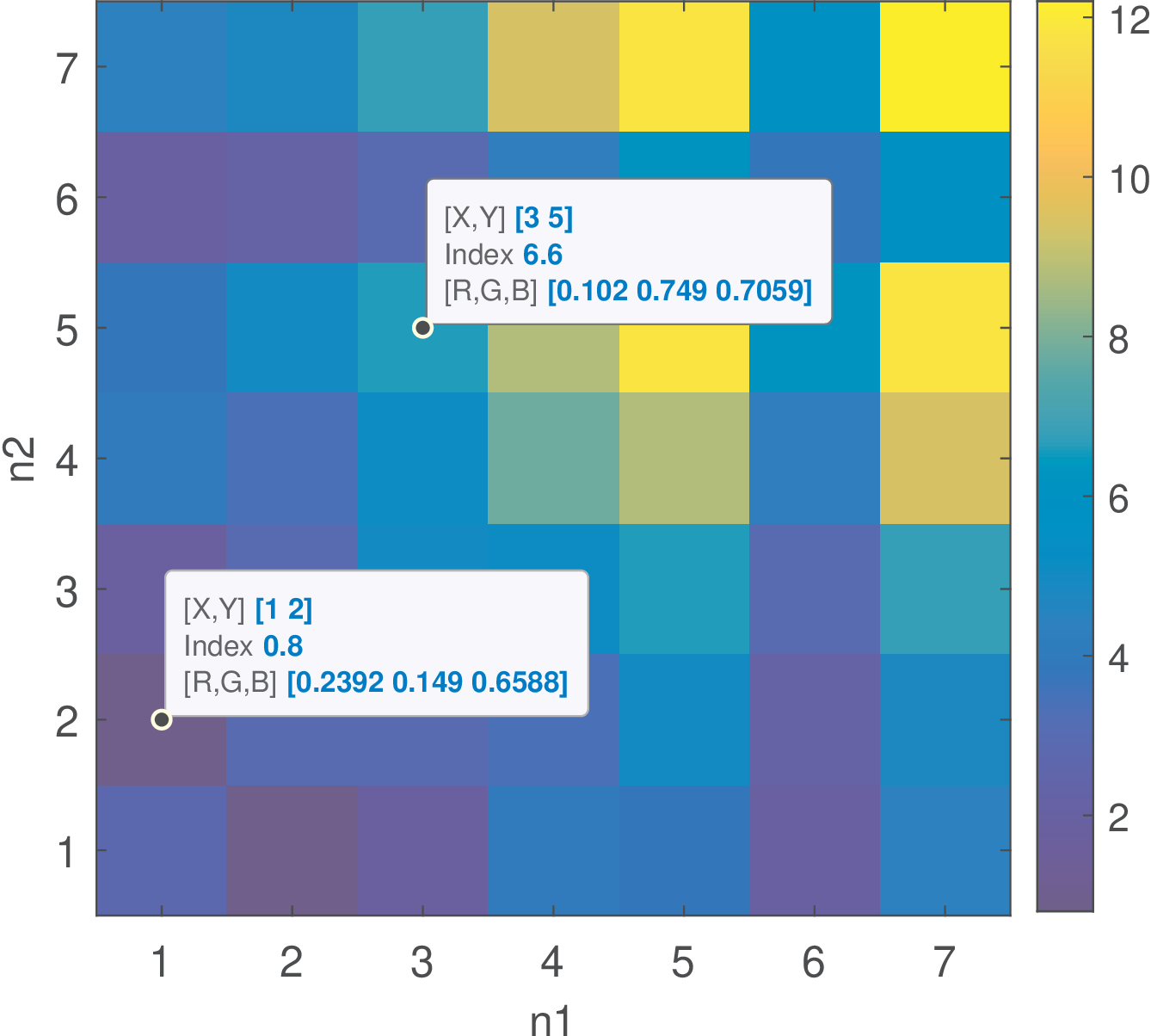
For real-valued processes, the autocorrelation is symmetric, as indicated in Figure B.7 and Figure B.8, while it would be Hermitian for complex-valued processes.
Two time instants: both absolute or one absolute and a relative (lag)
When characterizing second-order moments of a random process, instead of using two absolute time instants, it is sometimes useful to make one instant as a relative “lag” with respect to the other. For example, take two absolute instants and in Eq. (B.31). Alternatively, the same pair of instants can be denoted by considering as the absolute time that provides the reference instant and a lag indicating that the second instant is separated by 3 from the reference.
Using this scheme, Eq. (B.31) can be written as
|
| (B.33) |
Similarly, Eq. (B.32) can be denoted as
|
| (B.34) |
with and , where is the lag in discrete-time.
Example B.5. Contrasting two different representations of autocorrelations. Figure B.7 is a graph that corresponds to Eq. (B.32), with two absolute time instants. When using the alternative representation of Eq. (B.34), with a lag, the resulting matrix is obtained by rearranging the elements of the autocorrelation matrix. Figure B.9 compares the two cases. Note that the name autocorrelation matrix is reserved for the one derived from Eq. (B.32) (and Eq. (B.31)) that is, for example, symmetric.
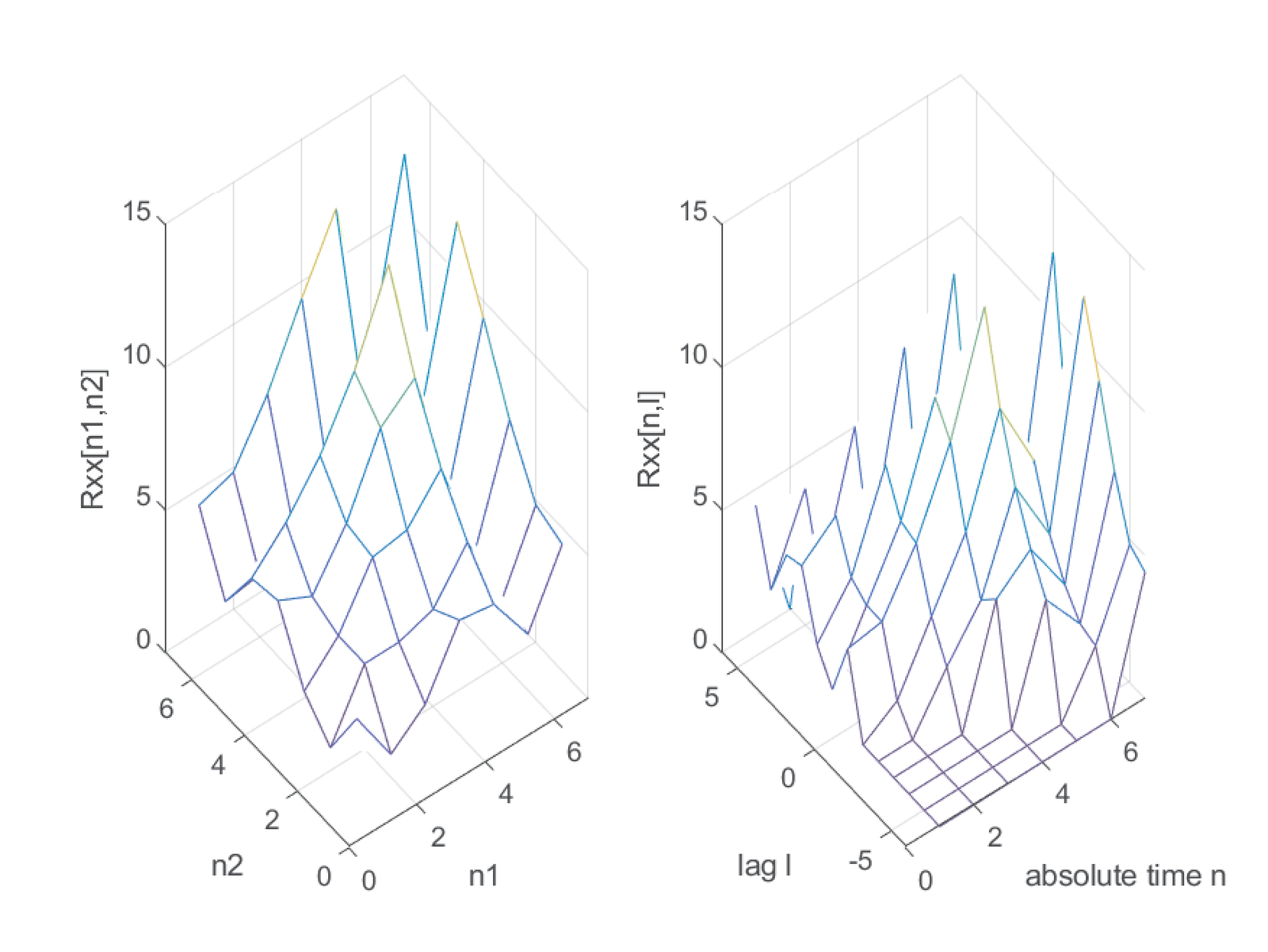
Figure B.10 is an alternative view of Figure B.9, which makes visualization easier. It better shows that Eq. (B.34) leads to shifting the column of the autocorrelation matrix (Figure B.7) corresponding to each value of interest.
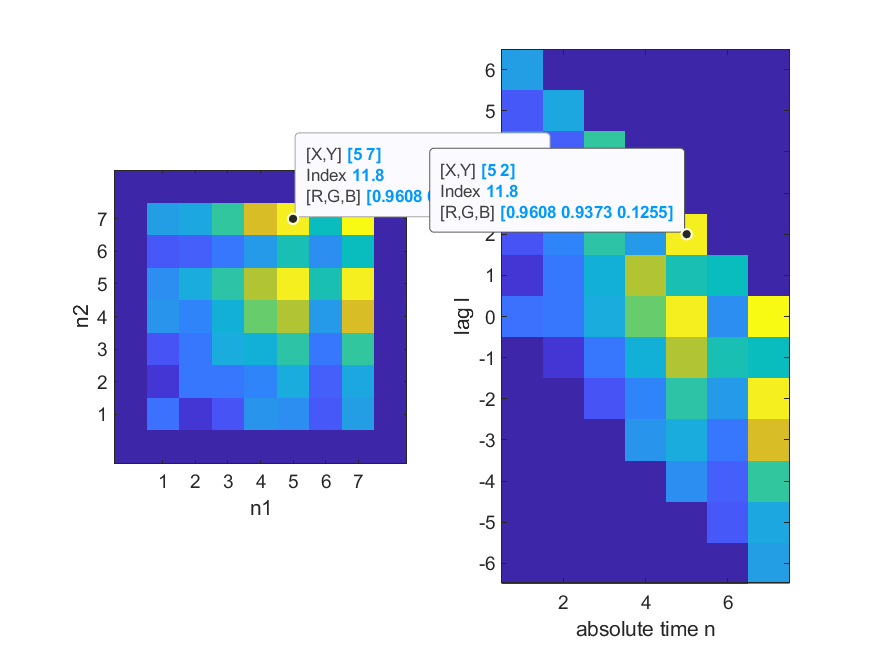
Properties such as the symmetry of the autocorrelation matrix may not be so evident from the right-side representation of Figure B.10 as in the left-side representation, but both are useful in distinct situations.
Covariance matrix
Similar to autocorrelation functions, it is possible to define covariance functions that expand the definition for random variables such as Eq. (1.48) and take as arguments two time instants of a random process. For example, for a complex-valued discrete-time process the covariance is
|
| (B.35) |
Stationarity, cyclostationarity and ergodicity
A random process is a powerful model. Hence, an important question is what information is necessary to fully characterize it. Take the matrix in Example B.3: this data does not fully characterize the random process because it consists of only five realizations (tossing a coin five times does not allow to estimate its probability of heads robustly). We would need an infinite number of realizations if we insist in characterizing it in a tabular form. The most convenient alternative is to describe it through pdfs. We should be able to indicate, for all time , the pdf of . Besides, for each time pair , the joint pdf should be known. The same for the pdf of each triple and so on. It can be noted that a general random process requires a considerable amount of statistics to be fully described. So, it is natural to define particular and simpler cases of random processes as discussed in the sequel.
An important property of a random process is the stationarity of a statistics, which means this statistics is time-invariant even though the process is random. More specifically, a process is called -th order stationary if the joint distribution of any set of of its random variables is independent of absolute time values, depending only on relative time.
A first-order stationary process has the same pdf (similar is valid for discrete-time). Consequently, it has a constant mean
|
| (B.36) |
constant variance and other moments such as .
A second-order stationary process has the same joint pdf . Consequently, its autocorrelation is
|
| (B.37) |
where the time difference is called the lag and has the same unit as in . Note that, in general, of Eq. (B.33) depends on two parameters: and . However, for a stationary process, Eq. (B.37) depends only on the lag because, given , is the same for all values of .
Similarly, if a discrete-time process is second-order stationary, Eq. (B.34) can be simplified to
|
| (B.38) |
where is the lag.
A third-order stationary process has joint pdfs that do not depend on absolute time values and so on. A random process is said to be strict-sense stationary (SSS) or simply stationary if any joint pdf is invariant to a translation by a delay . A random process with realizations that consist of i. i. d. random variables (called an i. i. d. process) is SSS. A random process that is not SSS is referred to as a non-stationary process even if some of its statistics have the stationarity property.
The SSS process has very stringent requirements, which are hard to verify. Hence, many real-world signals are modeled as having a weaker form of stationarity called wide-sense stationarity.
Basically, a wide-sense stationary (WSS) process has a mean that does not vary over time and an autocorrelation that does not depend on absolute time, as indicated in Eq. (B.36) and Eq. (B.37), respectively. Broadly speaking, wide-sense theory deals with moments (mean, variance, etc.) while strict-sense deals with probability distributions. Note that SSS implies WSS but the converse is not true in general, with Gaussian processes being a famous exception.
For example, the process corresponding to Figure B.7 is not WSS: its autocorrelation does not depend only on the time difference .
Example B.6. The autocorrelation matrix of a WSS process is Toeplitz. For a WSS process, elements of its autocorrelation matrix depend only on the absolute difference and, therefore, the matrix is Toeplitz. In this example, the function toeplitz.m is used to visualize the corresponding autocorrelation matrix as an image. For example, the command Rx=toeplitz(1:4) generates the following real-valued matrix:
Rx=[1 2 3 4 2 1 2 3 3 2 1 2 4 3 2 1].
Usually, the elements of the main diagonal correspond to .
To visualize a larger matrix, Figure B.11 was generated with Rxx=toeplitz(14:-1:4).
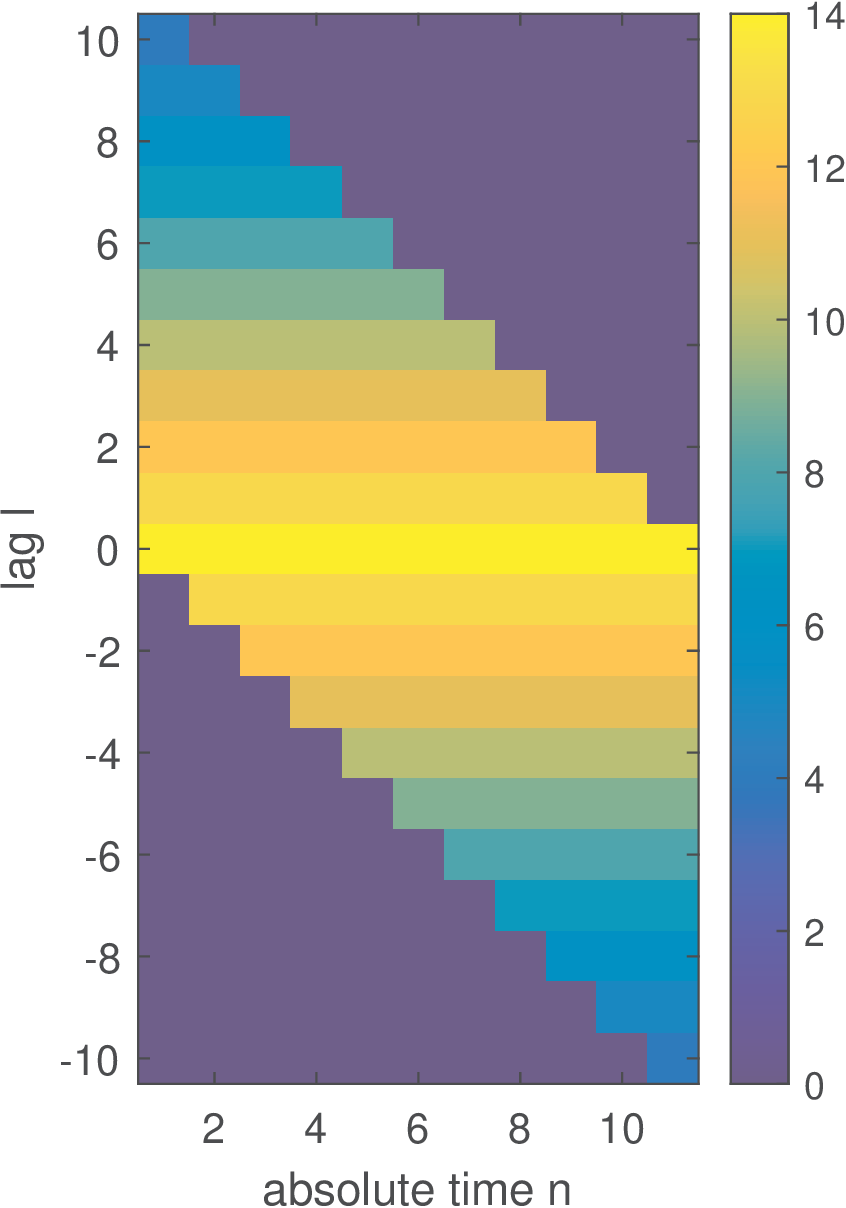
Given the redundancy in Figure B.11, one can observe that for a WSS, it suffices to describe for each value of the lag .
A cyclostationary process is a non-stationary process having statistical properties that vary periodically (cyclically) with time. In some sense it is a weaker manifestation of a stationarity property.
A given statistics (variance, autocorrelation, etc.) of a random process is ergodic if its time average is equal to the ensemble average. For example, an i. i. d. random process is ergodic in the mean.4 And, loosely speaking, a WSS is ergodic in both mean and autocorrelation if its autocovariance decays to zero.5
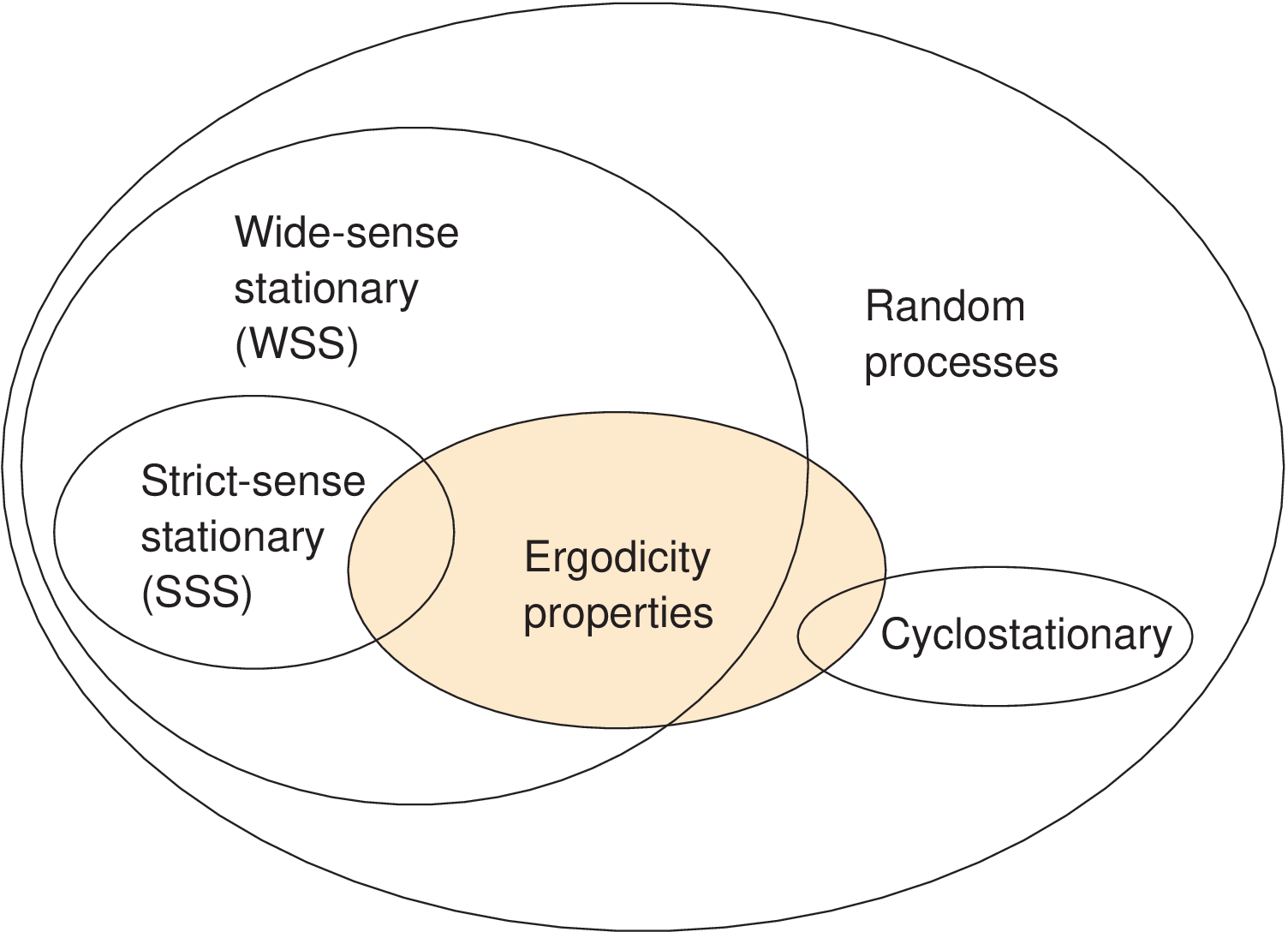
A process could be called “ergodic” if all ensemble and time averages are interchangeable. However, it is more pedagogical to consider ergodicity as a property of specific statistics, and always inform them.6 Even non-stationary or cyclostationary processes can be ergodic in specific statistics such as the mean. Figure B.12 depicts the suggested taxonomy of random processes using a Venn diagram.
Example B.7. Polar and unipolar bitstreams modeled as WSS processes. This example is based on processes used in digital communications to represent sequences of bits.
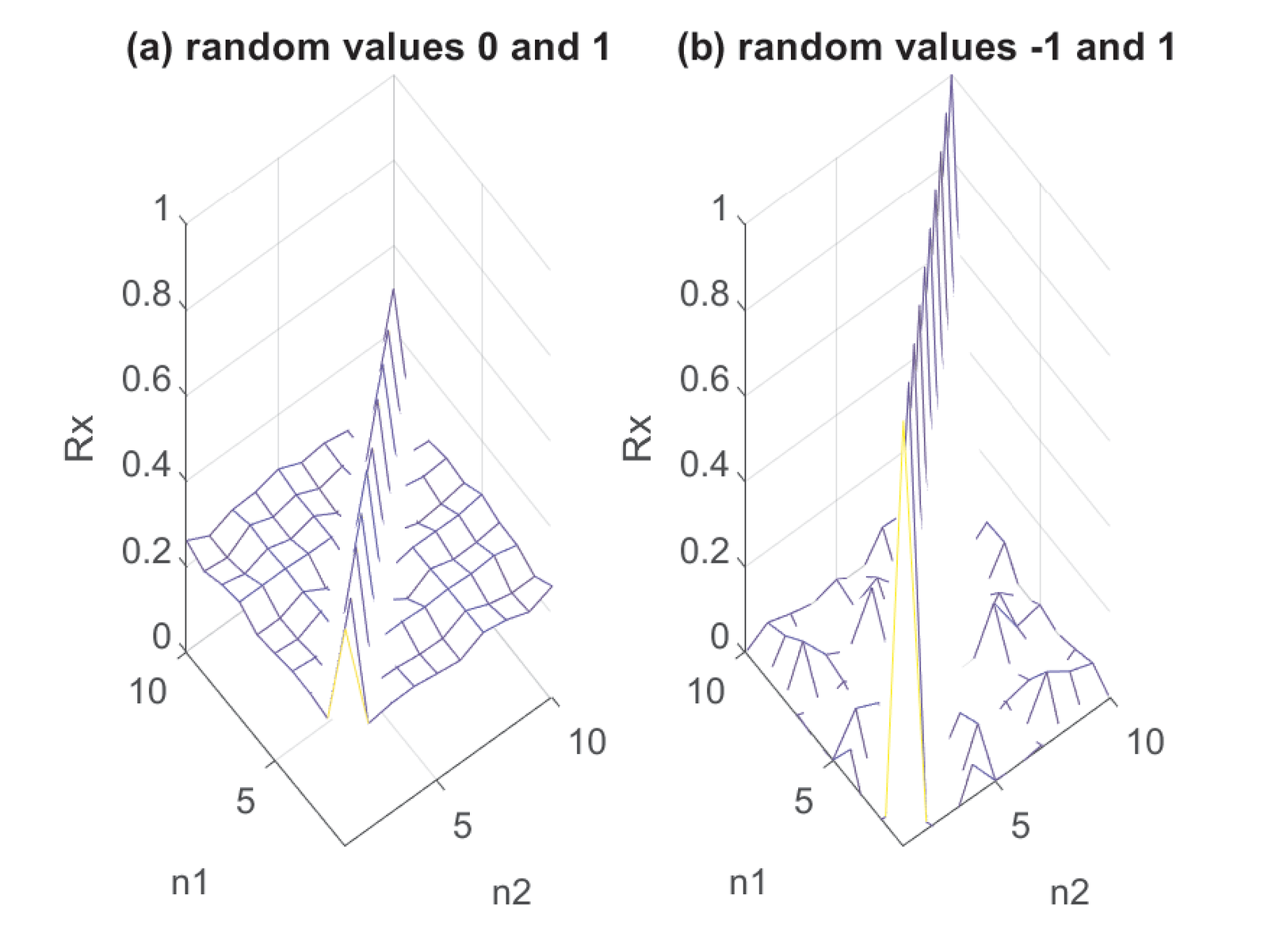
Figure B.13 illustrates two processes for which the main diagonal has the same values. The process (a) (left-most) is called a unipolar line code and consists of sequences with equiprobable values 0 and 1, while for the second process (called polar) the values are and 1.
For the unipolar and polar cases, the theoretical correlations for are 0.5 and 1, respectively. The result is obtained by observing that and for the unipolar case, is 0 or 1. Because the two values are equiprobable, . For the polar case, always and . The values of for are obtained by observing the values of all possible products . For the unipolar case, the possibilities are , , and , all with probability 1/4 each. Hence, for this unipolar example, . For the polar case, the possibilities are , , and , all with probability 1/4 each. Hence, for this polar example, .
In summary, for the polar code for and 0 otherwise. For the unipolar code, for and 0.25 otherwise.
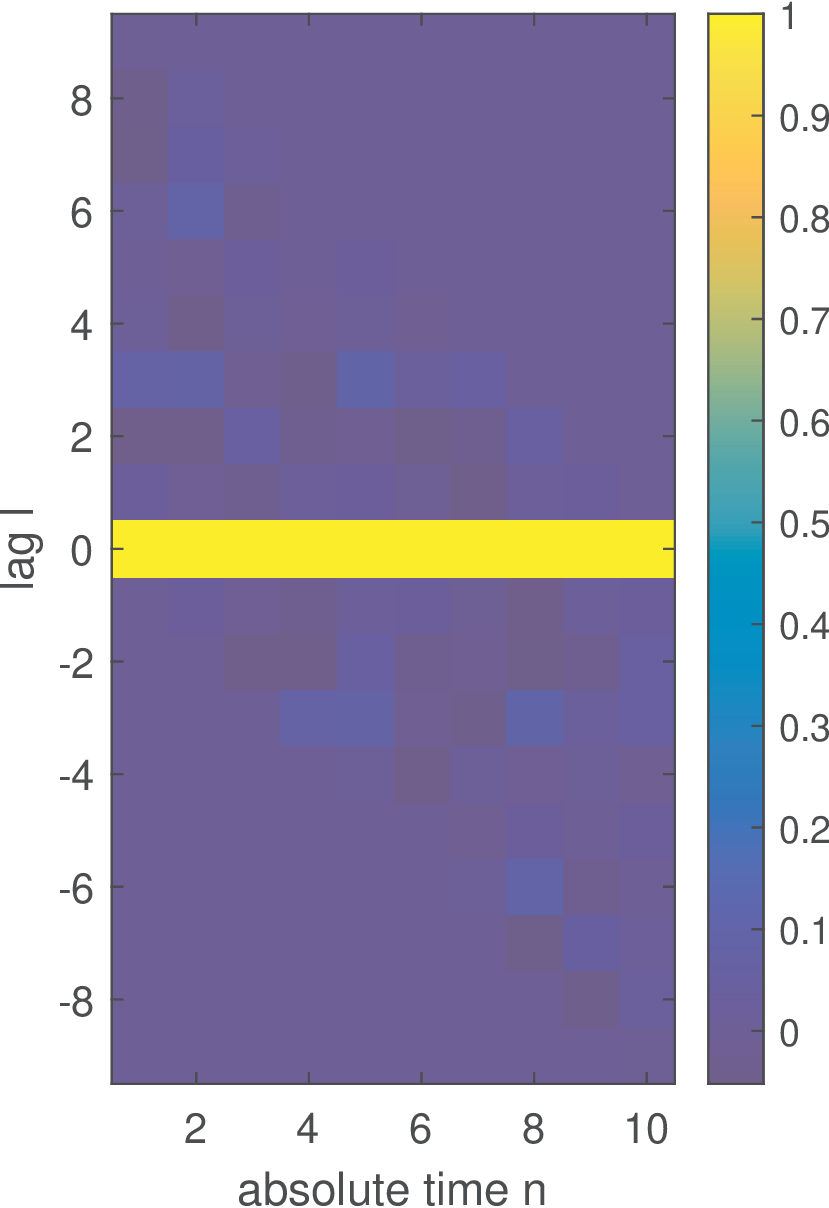
A careful observation of Figure B.13 indicates that two dimensions are not necessary and it suffices to describe as in Eq. (B.34). As discussed previously, in the case of WSS processes, the correlation depends only on the difference between the “time” instants and . Figure B.14 emphasizes this aspect using another representation for the polar case in Figure B.13.
Because the polar and unipolar processes that were used to derive Figure B.13 are WSS, Listing B.2 can be used to take advantage of having depending only on the lag and convert this matrix to an array .
1function [Rxx_tau, lags] = ak_convertToWSSCorrelation(Rxx) 2% function [Rxx_tau,lags]=ak_convertToWSSCorrelation(Rxx) 3%Convert Rxx[n1,n2] into Rxx[k], assuming process is 4%wide-sense stationary (WSS). 5%Input: Rxx -> matrix with Rxx[n1,n2] 6%Outputs: Rxx_tau[lag] and lag=n2-n1. 7[M,N]=size(Rxx); %M is assumed to be equal to N 8lags=-N:N; %lags 9numLags = length(lags); %number of lags 10Rxx_tau = zeros(1,numLags); %pre-allocate space 11for k=1:numLags; 12 lag = lags(k); counter = 0; %initialize 13 for n1=1:N 14 n2=n1+lag; %from: lag = n2 - n1 15 if n2<1 || n2>N %check 16 continue; %skip if out of range 17 end 18 Rxx_tau(k) = Rxx_tau(k) + Rxx(n1,n2); %update 19 counter = counter + 1; %update 20 end 21 if counter ~= 0 22 Rxx_tau(k) = Rxx_tau(k)/counter; %normalize 23 end 24end
Figure B.15 was generated using Listing B.2 for the data in Figure B.13.
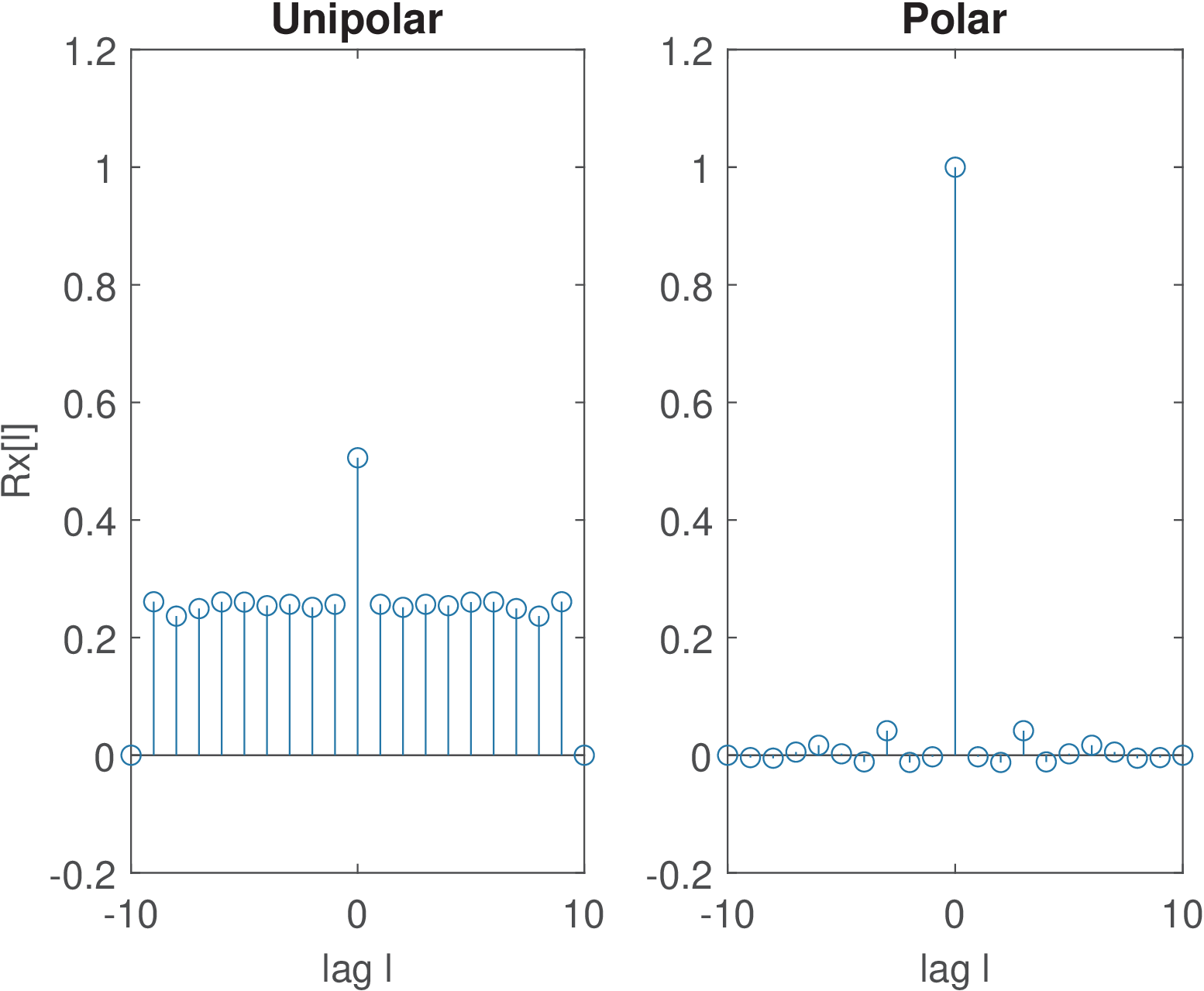
If ergodicity can be assumed, a single realization of the process can be used to estimate the ACF. Figure B.16 was generated using the code below, which generates a single realization of each process:
1numSamples=1000; 2Xunipolar=floor(2*rand(1,numSamples)); %r.v. 0 or 1 3[Rxx,lags]=xcorr(Xunipolar,9,'unbiased');%Rxx for unipolar 4subplot(121); stem(lags,Rxx) title('Unipolar'); 5Xpolar=2*[floor(2*rand(1,numSamples))-0.5]; %r.v. -1 or 1 6[Rxx,lags]=xcorr(Xpolar,9,'unbiased'); %Rxx for polar code 7subplot(122); stem(lags,Rxx) title('Polar');
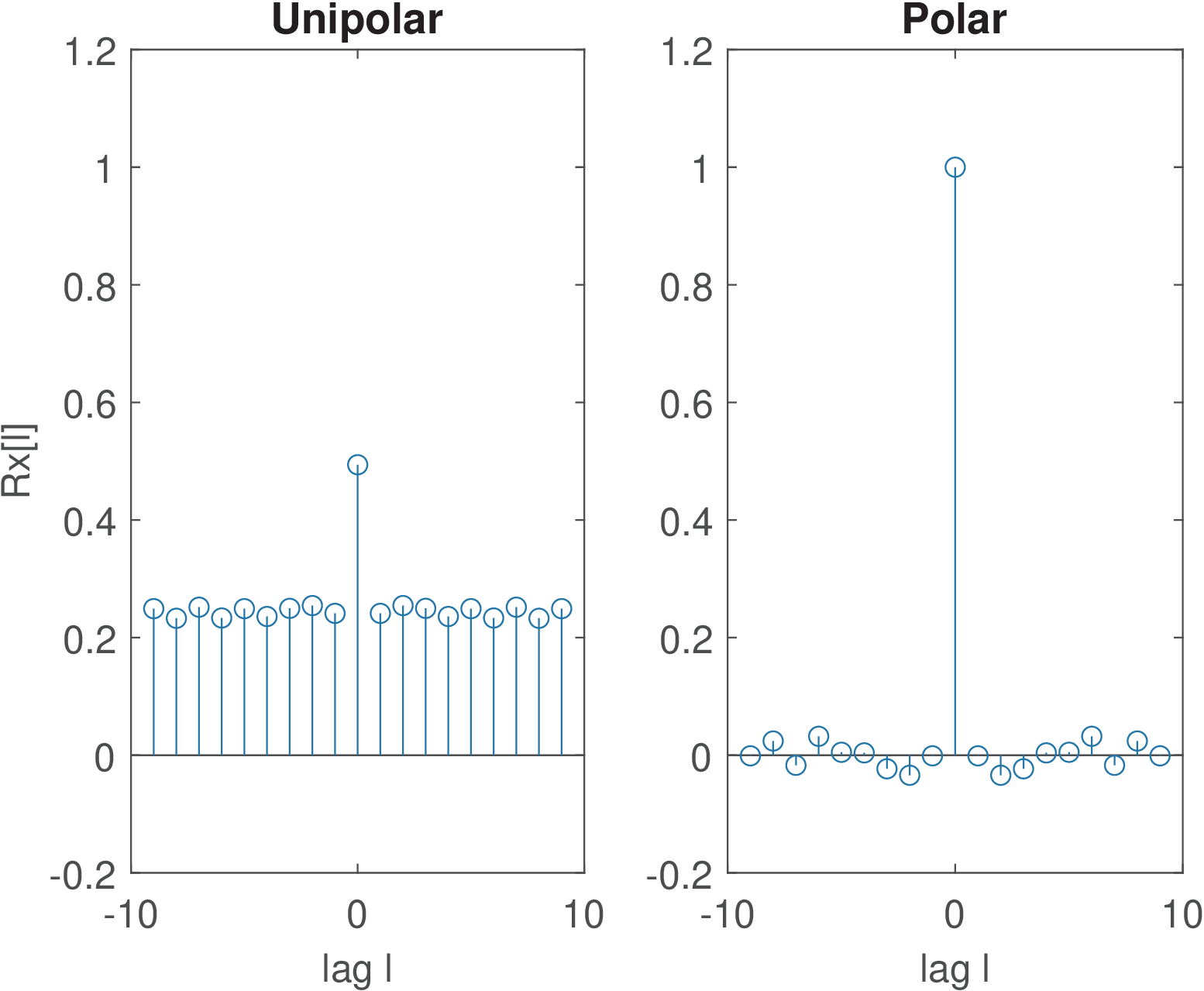
Increasing the number of samples to numSamples=1e6 achieves estimation errors smaller than in Figure B.16.