A.12 Linear Algebra
A.12.1 Inner products and norms
In general, a norm is a function (also denoted as ) that takes a vector and outputs a non-negative real number . The norm is often interpreted as the distance between and the adopted origin. A norm can be defined for any real or complex vector space, and the vector will belong to this adopted vector space. For example, assuming the Euclidean space and a vector with real-valued elements, the so-called L2 norm is denoted as .
Another useful norm is the Manhattan norm , also known as the L1 norm, which correspond to the sum of the absolute values of the elements in vector .
A third common norm is the maximum norm , also known as the infinity norm or Chebyshev norm, which measures the maximum distance along any dimension of the vector. For example, the maximum norm of is .
To be a valid norm, the function needs to have some fundamental properties: a) ; b) if then is the zero vector; c) and d) (triangle inequality) .
The inner product in a -dimensional space with complex-valued vectors is:
|
| (A.29) |
See Table 2.2 for alternative definitions of inner products.
When , Eq. (A.29) can be written as
|
| (A.30) |
An inner product can also be written as a multiplication of two vectors
|
| (A.31) |
where in this case both are assumed to be column vectors (row vectors would suggest ).
In case a vector is obtained via multiplication by a unitary matrix , Eq. (A.30) and Eq. (A.31) lead to
|
| (A.32) |
because , which indicates that the unitary does not alter the norm of the input vector.
A.12.2 Projection of a vector using inner product
To explore the properties and advantages of linear transforms, it is useful to study the vector projection (or simply projection) of a vector onto another one.
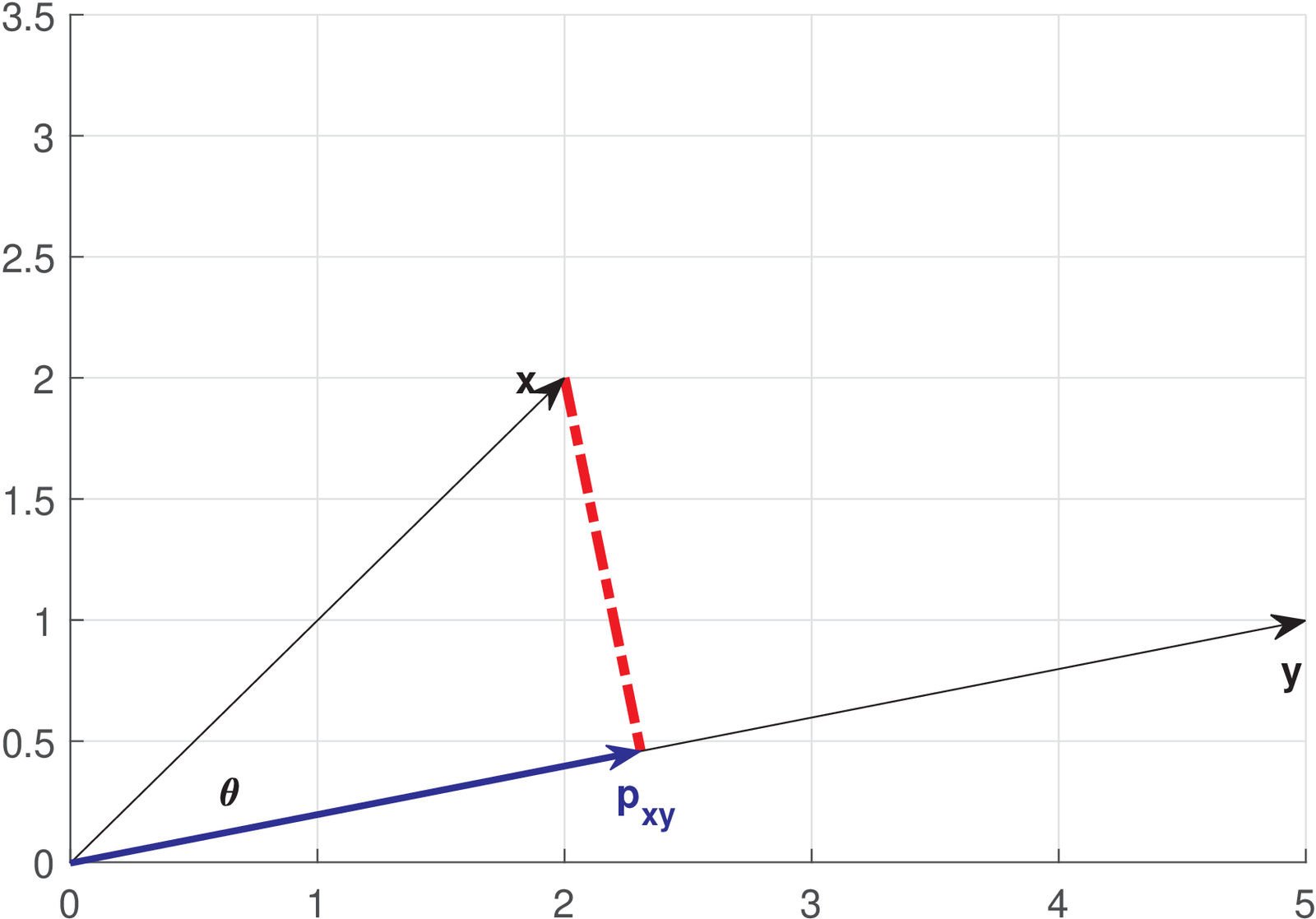
Using for simplicity, note that the projection of a vector in another vector is obtained by choosing the point along the direction of that has the minimum distance to . This line is perpendicular to , as indicated in Figure A.1. Using the Pythagorean theorem and assuming that , the norm of the projection can be written as . If , . Hence, in general,
|
| (A.33) |
For a given norm , the larger the inner product, the larger the norm of the projection. The same is valid for as depicted in Figure A.2:
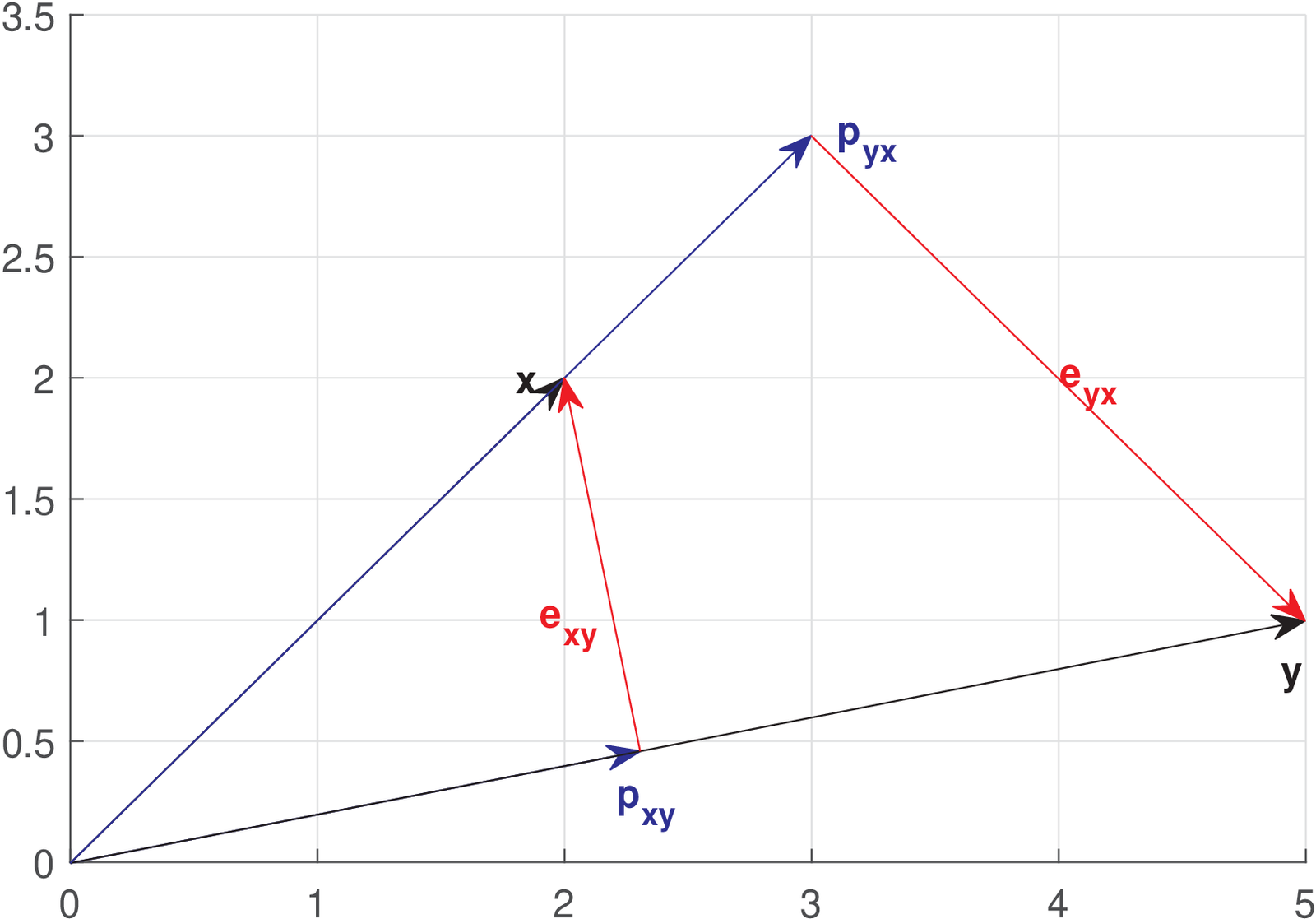
Any vector can be written as its norm multiplied by a unity norm vector that indicates its direction. Note that the vector is in the same or the opposite direction of , which can be specified by the unity norm vector . Hence, one has
where is a scaling factor that can be negative but does not change the direction of . Similarly, the projection of onto is given by
Note that if the vector has unitary norm, the absolute value of the inner product coincides with the norm . These expressions are valid for other vector spaces, such as , .
Using geometry to interpret a projection vector is very useful. When one projects in , the result is the “best” representation (in the minimum distance sense, or least-square sense) of that alone can provide. The error vector is orthogonal to (and, consequently, to ), i. e., . The vector represents what should be added to in order to completely represent , and the orthogonality indicates that cannot contribute any further.
Figure A.2 completes the example. It was obtained using the following Matlab/Octave script.1 The example assumes and , having an angle of approximately 33.7 degrees between them.
1x=[2,2]; %define a vector x 2y=[5,1]; %define a vector y 3magx=sqrt(sum(x.*x))%magnitude of x 4magy=sqrt(sum(y.*y))%magnitude of y 5innerprod=sum(x.*y) %<x,y>=||x|| ||y|| cos(theta) 6theta=acos(innerprod / (magx*magy)) %angle between x and y 7%obs: could use acosd to have angle in degrees 8disp(['Angle is ' num2str(180*theta/pi) ' degrees']); 9%check if inverting direction is needed: 10invertDirection=1; if theta>pi/2 invertDirection=-1; end 11%find the projection of x over y (called p_xy) and p_yx 12mag_p_xy = magx*abs(cos(theta)) %magnitude of p_xy 13%directions: obtained as y normalized by magy, x by magx 14y_unitary=y/magy; %normalize y by magy to get unitary vec. 15p_xy = mag_p_xy * y_unitary* invertDirection %p_xy 16mag_p_yx = magy*abs(cos(theta)); %magnitude of p_yx 17x_unitary=x/magx; %normalize x by magx to get unitary vec. 18p_yx = mag_p_yx * x_unitary* invertDirection %p_yx 19%test orthogonality of error vectors: 20error_xy = x - p_xy; %we know: p_xy + error_xy = x 21sum(error_xy.*y) %this inner product should be zero 22error_yx = y - p_yx; %we know: p_yx + error_yx = y 23sum(error_yx.*x) %this inner product should be zero
The concept of projections via inner products will be extensively used in our discussion about transforms. For example, the coefficients of a Fourier series of a signal correspond to the normalized projections of on the corresponding basis functions. A large value for the norm of a projection indicates that the given basis function provides a good contribution in the task of representing .
Chapter 2 discusses block transforms and relies on orthogonal functions. Hence, it is useful to discuss why orthogonality is important.
A.12.3 Orthogonal basis allows inner products to transform signals
Assume the existence of a set of orthogonal vectors composing the basis of a vector space. For example, in , a convenient basis is the standard, composed by and . The inner product indicates that these two vectors are orthogonal. The orthogonality property simplifies the following analysis task: given any vector , the coefficients and of the linear combination , can be easily found by using the dot products and . The following theorem proves this important result.
Theorem 4. Analysis via inner products. If the basis set of an inner product space (e. g., Euclidean) is orthonormal, the coefficients of a linear combination that generates a vector can be calculated by the inner product between and the respective vector in the basis set.
Proof: Recall the following properties of a dot product: and and write
because the basis vectors are orthonormal, if and if . Therefore,
because all the terms in the above summation are zero but the one for .
Example A.1. Obtaining the coefficients of a linear combination of basis functions. A simple example can illustrate the analysis procedure: the coefficients of are and by inspection, but they could be calculated as and . Note that the zeros in these basis vectors make the calculation overly simple. Another example may be more useful to highlight orthogonality and the following alternative basis set is assumed: and . Let . Given , the task is again to find the coefficients such that . Due to the orthonormality of and , one can for example obtain . These computations can be done in Matlab/Octave as follows.
1i=[0.5,0.866], j=[0.866 -0.5] %two orthonormal vectors 2x=3*i+2*j %create an arbitrary vector x to be analyzed 3alpha=sum(x.*i), beta=sum(x.*j) %find inner products
In contrast, let us modify the previous example, adopting a non orthogonal basis. Assume that and (note that , hence the vectors are not orthogonal). Let . In this case, and , which do not coincide with the coefficients and . How could the coefficients be properly recovered in this case? An alternative is to write the problem as a set of linear equations, organize it in matrix notation and find the coefficients by inverting the matrix. In Matlab/Octave:
1i=transpose([1,1]), j=transpose([0,1]) %non-orthogonal 2x=3*i+2*j %create an arbitrary vector x to be analyzed 3A=[i j]; %organize basis vectors as a matrix 4temp=inv(A)*x; alpha=temp(1), beta=temp(2) %coefficients
In summary, the analysis procedure for many linear transforms (such as Fourier, Z, etc.) obtain the coefficients via an inner product, and the procedure can be interpreted as calculating the projection of onto basis (eventually scaled by the norm of ).
This discussion leads to the conclusion that a basis with orthogonal vectors significantly simplifies the task: in this case, the analysis procedure can be done via inner products. This applies when the basis vectors do not have unitary-norm, but in this case a normalization by their norms is needed. Orthogonal basis vectors are a property of all block transforms discussed in this text.
A.12.4 Moore-Penrose pseudoinverse
Pseudoinverses2 are generalizations of the inverse matrix and are useful when the given matrix does not have an inverse (for example, when the matrix is not square or full rank).
The Moore-Penrose pseudoinverse has several interesting properties and is adequate to least square problems. It provides the minimum-norm least squares solution to the problem of finding a vector that minimizes the error vector norm . Assuming is an matrix, the pseudoinverse provides the solution for a set of overdetermined or underdetermined equations if or , respectively.
Two properties of a Moore-Penrose pseudoinverse are
|
| (A.34) |
and
|
| (A.35) |
With being the rank of , then:
- if and , the pseudoinverse is equivalent to the usual inverse;
-
if (overdetermined) and, besides, (the columns of are linearly independent), is invertible and using Eq. (A.34) the pseudoinverse is given by
(A.36) -
if (underdetermined) and (the rows of are linearly independent), is invertible and using Eq. (A.35) leads to
(A.37)
Whenever available, instead of Eq. (A.36) or Eq. (A.37) that requires linear independence, one should use a robust method to obtain such as the pinv function in Matlab/Octave, which adopts a SVD decomposition to calculate . Listing A.3 illustrates such calculations and the convenience of relying on pinv when the independence of rows or columns is not guaranteed.
1test=3; %choose the case below 2switch test 3 case 1 %m>n (overdetermined/tall) and linearly indepen. columns 4 X=[1 2 3; -4+1j -5+1j -6+1j;1 0 0;0 1 0]; %4 x 3 5 case 2 %n>m (underdetermined/fat) and linearly independent rows 6 X=[1 2 3; -4+1j -5+1j -6+1j]; %2 x 3 7 case 3 %neither rows nor columns of X are linearly independent 8 %rows X(2,:)=2*X(1,:) and columns X(:,4)=3*X(:,1) 9 X=[1 2 3 3; 2 4 6 6; -4+1j -5+1j -6+1j -12+3*1j]; %3 x 4 10end 11Xp_svd = pinv(X) %pseudoinverse via SVD decomposition 12Xp_over = inv(X'*X)*X' %valid when columns are linearly independent 13Xp_under = X'*inv(X*X') %valid when rows are linearly independent 14rank(X'*X) %X'*X is square but may not be full rank 15rank(X*X') %X*X' is square but may not be full rank 16Xhermitian=X'*X*pinv(X) %equal to X' (this property is always valid) 17Xhermitian2=pinv(X)*X*X' %equal to X' (the property itself is valid) 18maxError_over=max(abs(Xp_svd(:)-Xp_over(:))) %error for overdetermin. 19maxError_under=max(abs(Xp_svd(:)-Xp_under(:))) %for underdetermined