A.28 Fixed and Floating-Point Number Representations
A.28.1 Representing numbers in fixed-point
Both fixed and floating-point representations are capable of representing real numbers. A real number can be written as the sum of an integer part and a fractional part that is less than one and non-negative.
The name “fixed-point” is due to the fact that the bits available to represent a number are organized as follows:
- 1 bit representing the sign (positive or negative) of the integer part and, consequently, of the number itself
- bits representing the integer part of the number
- bits representing the fractional part of the number
such that bits. For simplicity, the sign bit is assumed here to be the MSB, but in practice that depends on the adopted standard and the machine endianness (see Appendix B.2.3 for a brief explanation of big and little endian formats).
One way of thinking the “point” is that there is flexibility on choosing the power of 2 that is associated to the second bit, at the right of the MSB. After this design choice is made, a fictitious point separates the bits corresponding to the integer part from the fractional part bits. There is a convention of denoting the values chosen for and as Q..
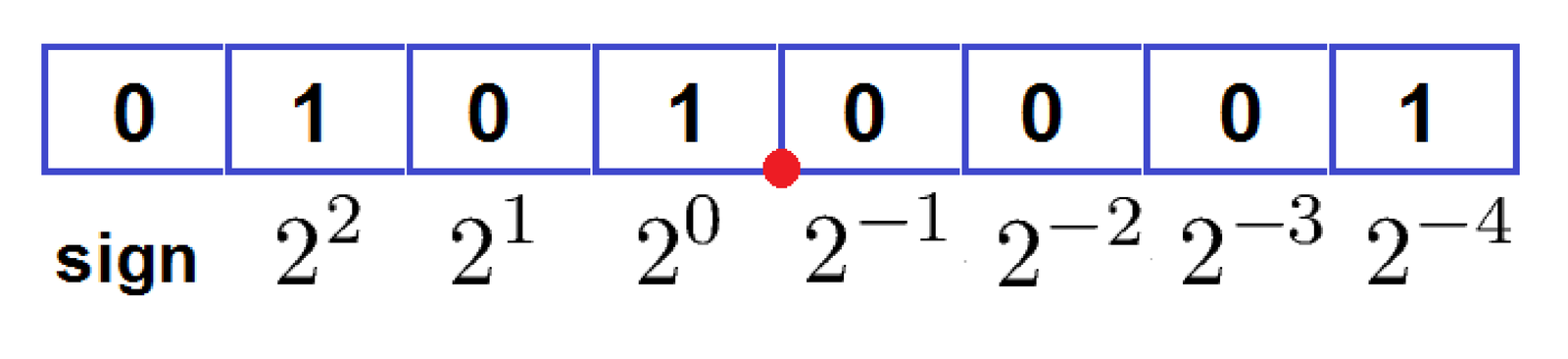
Figure A.37 shows an example of fixed-point representation using Q3.4, for which , and, consequently . In this case, the point is located between the fourth and fifth bits. The binary codeword is mapped to a real number according to the position of the point:
It is very common to normalize the numbers to make them fit the range . In this case can be zero, and the second bit has a weight in base-2 equals to such that the point is between the MSB and this bit. The other bit weights are then , according to their respective position. For example, the outputs of a quantizer with bits when represented in the format Q0.1 (, ) assume four possible outputs . In general, the weight of the LSB corresponds to the value of the step size, i. e.
|
| (A.125) |
Note that the number 5.0625 in Figure A.37 can also be obtained by identifying that corresponds to and calculating . If the point were moved to the position between the MSB and second bit, which corresponds to choosing Q0.7, the quantizer would have and the same codeword would be mapped to .
In summary, when a fixed-point representation is assumed, the quantizer has step and can output numbers in the range . Algorithm 1 describes the process for representing a real number in fixed-point using Q..
For example, using Algorithm 1 to represent in Q3.4, the first step is to calculate . Then, using round leads to , which corresponds to and in two’s complement. This algorithm is the same implemented in Listing 1.18 but explicitly outputs the binary codeword .
Choosing the point position depends on the dynamic range of the numbers that will be represented and processed. This is typically done with the help of simulations and is a challenging task due to the tradeoff between range (the larger the better) and precision (the larger the better). In sophisticated algorithms, it is typically required to assume distinct positions for the point at different stages of the process. In such cases, using specialized tools such as Mathwork’s Fixed-Point Designer [ url1mfi] can significantly help.
Example A.13. Fixed-point in Matlab and Octave. Both Matlab and Octave have toolboxes for fixed-point arithmetic. But, unfortunately, they are not compatible. Matlab’s Fixed-Point Toolbox is more sophisticated and better documented. If you have the Matlab’s toolbox, try for example doc fi. The Matlab command for representing as in the previous example is:
which outputs:
x_q = -7.437500000000000 DataTypeMode: Fixed-point: binary point scaling Signed: true WordLength: 8 FractionLength: 4 RoundMode: nearest OverflowMode: saturate ProductMode: FullPrecision MaxProductWordLength: 128 SumMode: FullPrecision MaxSumWordLength: 128 CastBeforeSum: true
Example A.14. Quantization example in Matlab. As another example, let volts be the amplitude of at , such that , where is the value of corresponding to . The value of quantized with bits and reserving bits to the integer part is , which can be obtained in Matlab with:
1format long %to better visualize numbers 2x=2804.6542; %define x 3xq=fi(x) %quantize with 16 bits and "best-precision" fraction length
When fi is used with a single argument, it assumes a 16-bit word length and it adjusts such that the integer part of the number can be represented (called in Matlab “best-precision” fraction length). For this example, the result is:
xq = 2.804625000000000e+03 Signedness: Signed WordLength: 16 FractionLength: 3
indicating that bits are used to represent the integer part of (2084), given that . Considering one bit is reserved for the sign, then bits, which is the FractionLength.
Octave users have to look after the Fixed Point Toolbox for Octave.26 Its syntax is a = fixed(bi, bf, x), where a is an object of class FixedPoint. The class field a.x stores the value in the regular floating point format.27 The Octave command for representing as in the previous example is:
It should be noted that the following commands bi=0; bf=1;a=fixed(bi,bf,0.4) output a=0 because fixed implements truncation (to 0) instead of rounding (to in this case). As another example, c=fixed(bi,bf,-0.6) outputs c=-1 ( was truncated to ). Following object-oriented programming (OOP) practice, one should be consistent when dealing with the objects. For example, a+4 returns an error message because a is an object, not a number, and a.x+4 should be used instead. On the other hand, a+c is a valid operation that returns when the objects were created with the previous commands.
A.28.2 IEEE 754 floating-point standard
Choosing the point position provides a degree of freedom for trading off range and precision in a fixed-point representation. However, there are situations in which a software needs to deal simultaneously with small and large numbers, and having distinct positions for the point all over the software is not practical or efficient. For example, if distances in both nanometers and kilometers should be manipulated with reasonable precision, the dynamic range of would require bits for the integer part or keeping track of two distinct point positions. Hence, in many cases, a floating-point representation is more adequate.
A number in floating point is represented as in scientific notation:
|
| (A.126) |
For example, assuming the base is 10 for simplicity, the number is interpreted as , where 1.234567 is the significand and 2 the exponent. While in fixed point the bits available to represent a signed number are split between and , in floating point the bits are split between the significand and exponent.
The key aspect of Eq. (A.126) is that, as the value of the exponent changes, the “point” has new positions and allows to play a different trade off between range and precision: the values a floating point can assume are not uniformly spaced. While fixed-point numbers are uniformly spaced by , which then imposes the maximum error within the range, the error magnitude in a floating point representation depends on the value of the exponent. For a given error in the significand representation, the larger the exponent, the larger the absolute error of with respect to the number it represents. This is a desired feature in many applications and floating point is used for example in all personal computers. The fixed point niche are embedded systems, where power consumption and cost have more stringent requirements.
The IEEE 754 standard for representing numbers and performing arithmetics in floating point is adopted in almost all computing platforms. Among other features,28 it provides support to single and double precision, which are typically called “float” and “double”, respectively, in programming languages such as C and Java.
The wide adoption of IEEE 754 is convenient because a binary file written with a given language in a given platform can be easily read with a distinct language in another platform. In this case, the only concern is to make sure the endianness is the same (Appendix B.2.3). The two following examples discuss numerical errors and quantization in practical scenarios.
Example A.15. Floating point representation in Matlab/Octave and numerical errors. Unless specified otherwise, Matlab/Octave uses double precision. For example, the commands clear all;x=3;whos generate the following output:
Variables in the current scope: Attr Name Size Bytes Class ==== ==== ==== ===== ===== x 1x1 8 double Total is 1 element using 8 bytes
in Octave and equivalent information in Matlab. As indicated, numbers in double precision use bits while are used in single precision (“float”). A double allocates 11 bits to the exponent and 52 to the significand, while in float precision these numbers are 8 and 23, respectively. The sign bit is used for the significand, but the exponent can also be a positive or negative number. Hence, one can consider that one exponent bit is used to represent its own sign.
The following Matlab/Octave code can be used to investigate the ranges for single and double precision:
1str = 'Ranges for double before and after 0:\n%g to %g and %g to %g'; 2sprintf(str, -realmax, -realmin, realmin, realmax) 3str = 'Ranges for float before and after 0:\n%g to %g and %g to %g'; 4sprintf(str,-realmax('single'),-realmin('single'), ... 5 realmin('single'), realmax('single'))
The output is:
ans = Ranges for double before and after 0: -1.79769e+308 to -2.22507e-308 and 2.22507e-308 to 1.79769e+308 ans = Ranges for float before and after 0: -3.40282e+038 to -1.17549e-038 and 1.17549e-038 to 3.40282e+038
From this output, it would be a mistake to consider that and for double and single precision, respectively. Recall that the floating point numbers are non-uniformly spaced.
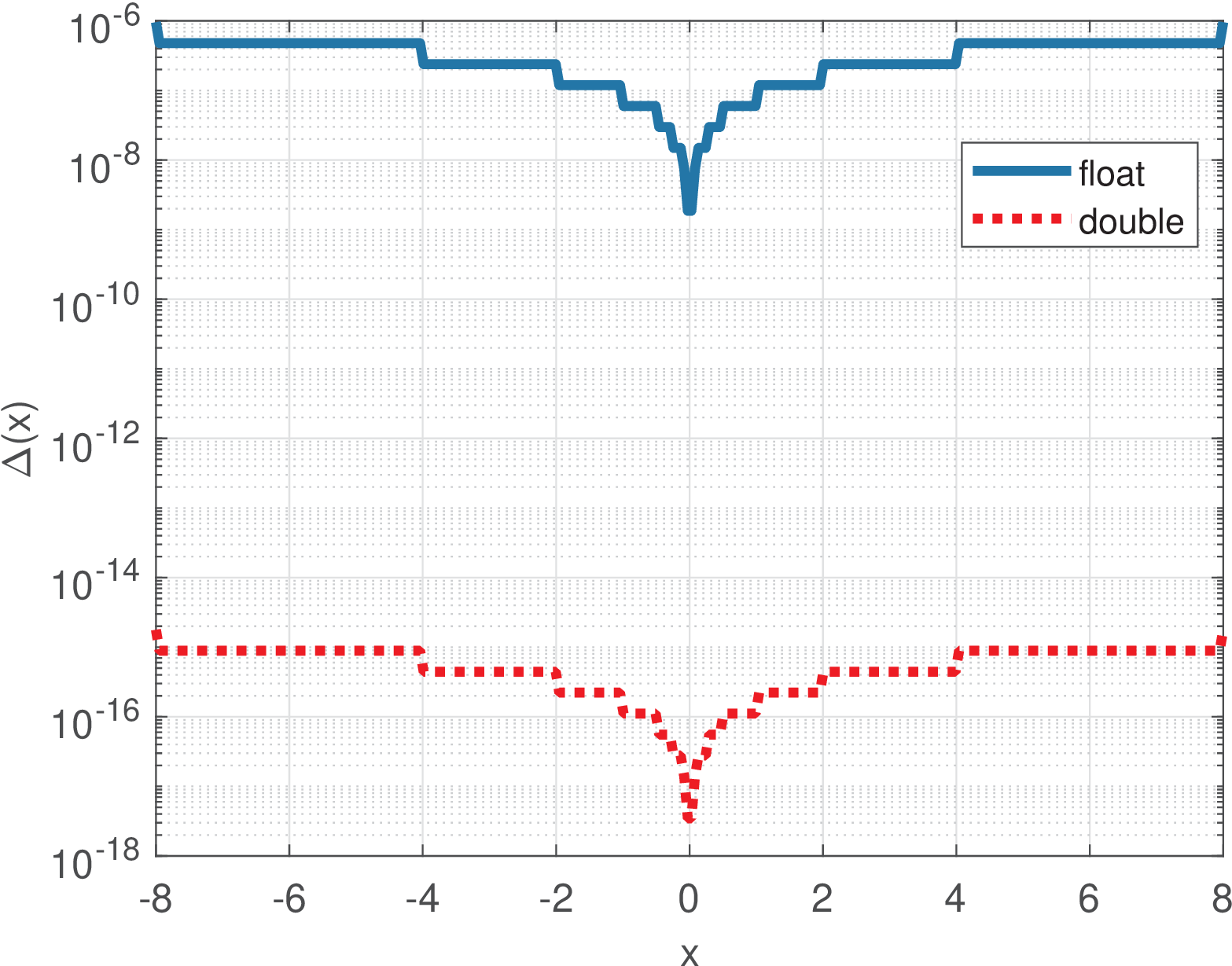
Given that the step varies from a number to the next number in floating point, Matlab/Octave provides the command eps(x) to obtain . Figure A.38 provides a comparison obtained with Listing A.17.
1N=300; delta_x=zeros(1,N); x=linspace(-8,8,N); %define range 2%use loops to be compatible with Octave. Matlab allows delta_x=eps(x) 3for i=1:N, delta_x(i) = eps(single(x(i))); end %single precision 4semilogy(x,delta_x); hold on 5for i=1:N, delta_x(i) = eps(x(i)); end %double precision 6semilogy(x,delta_x,'r:'); legend('float','double'); grid
Figure A.38 indicates that care must be exercised especially when dealing with single precision, which is a requirement of many DSP chips, for example. Even double precision can cause strange behavior. A good example is provided by Listing A.18, from Mathwork’s documentation [ url1flm].
1a = 0.0; %a uses double precision 2for i = 1:20 3 a = a + 0.1; %20 times 0.1 should be equal to 2 4end 5a == 2 %checking if a is 2 returns false due to numerical errors
The design of algorithms that are robust to numerical errors, such as matrix inversion, is the focus of many textbooks. Besides trying to adopt robust algorithms, a DSP programmer needs to always be aware of the possibility of numerical errors. Taking the example of the previous code, instead of a check such as if (a==2), it is often better to write
where eps corresponds to eps(1) and is the default when a better guess for the range of interest (eps(2) in the example) is not available.
It is possible to instruct Matlab/Octave to use single (using the function single) or double precision (the default) as illustrated in Listing A.19, which uses the FFT algorithm (to be discussed in Chapter 2) to compare the options with respect to speed.
1N=2^20; %FFT length (one may try different values) 2xs=single(randn(1,N)); %generate random signal using single precision 3xd=randn(1,N); %generate random signal using double precision 4tic %start time counter 5Xs=fft(xs); %calculate FFT with single precision 6disp('Single precision: '), toc %stop time counter 7tic %start time counter 8Xd=fft(xd); %calculate FFT with double precision 9disp('Double precision: '), toc %stop time counter
Note that benchmarking is tricky and using single precision may not be faster than double precision. On a given laptop, Listing A.19 executed on Matlab returned 0.073124 and 0.104728 seconds, which indicates that double precision was approximately 1.43 times slower than single precision. Executing the code on the same machine using Octave led to approximately 0.06 seconds to both double and single precision.