4.12 Applications
Application 4.1. FFT leakage and picket-fence effects. This application explores a script that illustrates the results discussed in Section 4.3.4.0 and can be found at folder Applications/FFTLeakagePicketFenceEffects. The version ak_window4_noGUI.m runs on both Matlab and Octave while ak_window4gui.m incorporates a Matlab GUI.13
Basically the software varies the frequency of a cosine and compares the magnitudes of its DTFT and FFT. The goal is to show how the cosine is represented by two frequency components , and the interaction of the corresponding “positive” and “negative” sinc functions for composing the DTFT by their sum. Also, the script indicates how the FFT discretizes the frequency axis, which creates the picket-fence effect, and the leakage that an FFT user observes when does not coincide with a frequency bin.
Figure 4.44 is a screenshot when the cosine frequency is rad and the corresponding DTFT magnitude. The cosine is represented by two spectral lines (tones), at normalized frequencies . The (dashed) reference line indicates the value given the FFT-length and cosine amplitude . Note that the DTFT, which is the sum of two sinc functions, surpasses this reference value for normalized frequencies around .
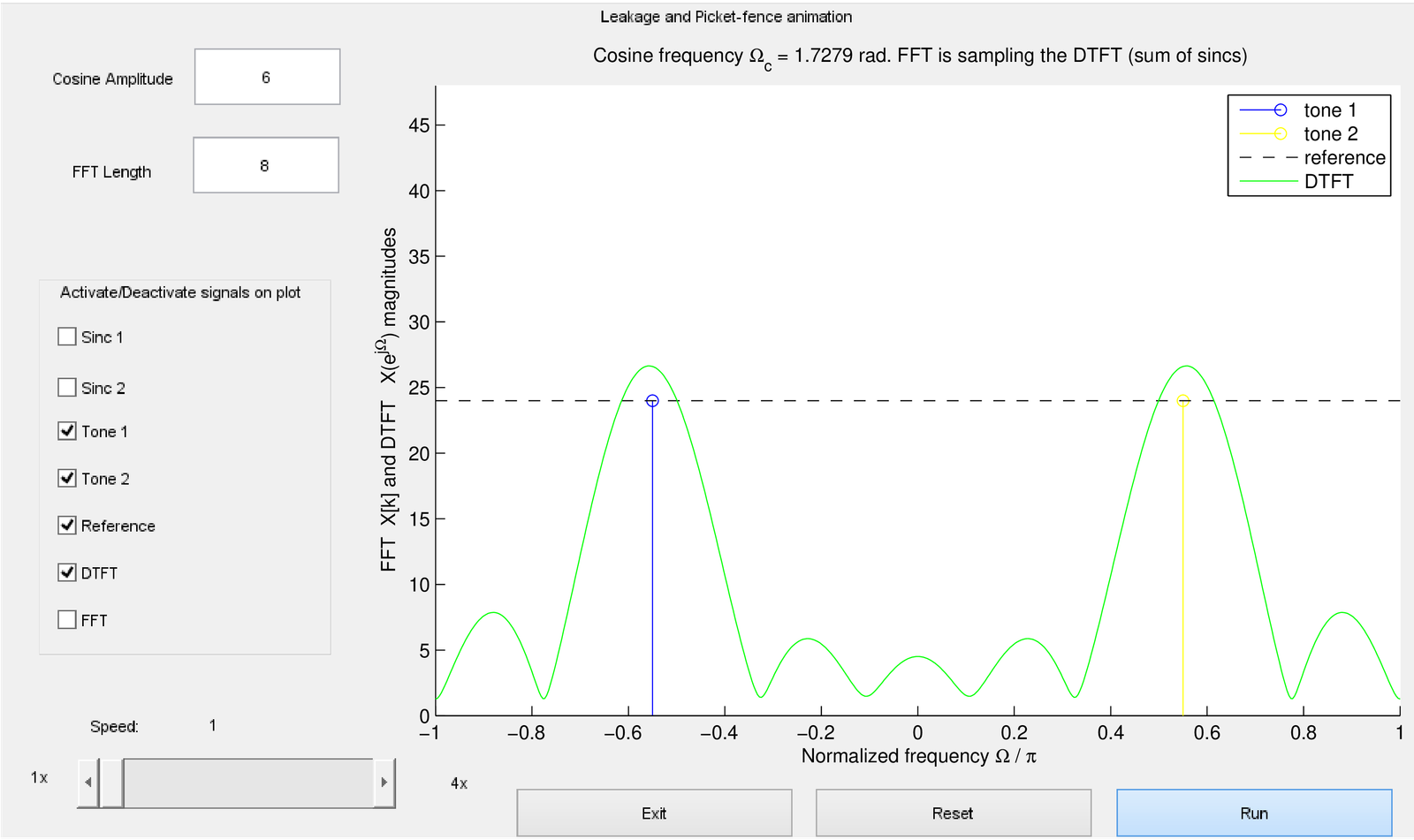
Figure 4.45 corresponds to a situation where rad and the FFT magnitude values are superimposed to the DTFT. Besides, the two sinc functions centered at normalized frequencies are also displayed such that one can see the DTFT being composed by their summation.
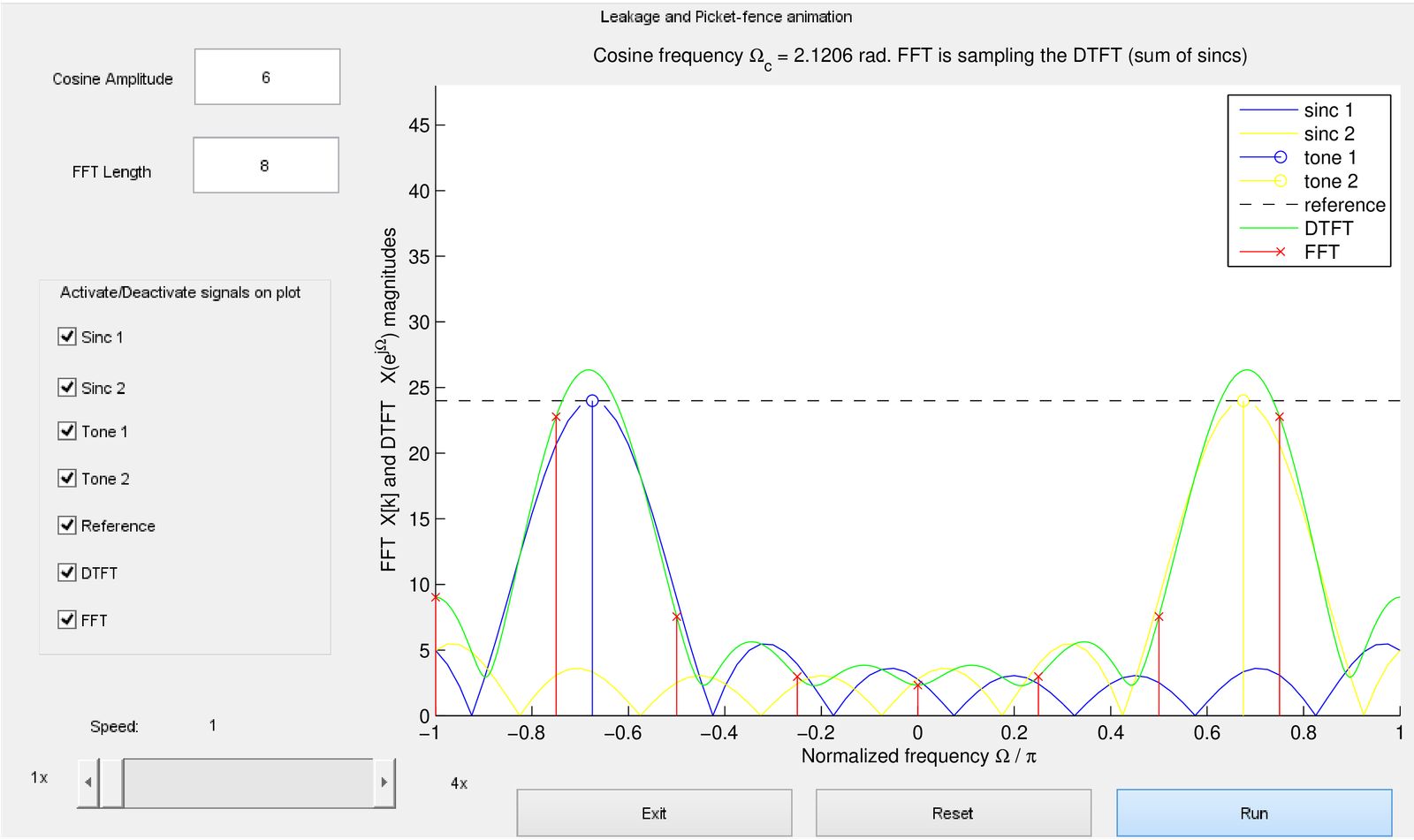
In Figure 4.45, does not coincide with an FFT bin and the leakage is observed by the FFT values, which are samples of the DTFT. The picket-fence is clearly seen because in this case the resolution is low, and only DTFT values in the range are obtained by the FFT. Increasing alleviates this effect. The reader is invited to run the code with different settings.
Application 4.2. Using Welch’s method to estimate the mean square (MS) spectrum. As explained, to decrease the variance of the estimated spectrum, it is useful to adopt Welch’s method. In this case, one should consider the effect of the window of samples on the estimation.
In Matlab/Octave it is convenient to estimate a MS spectrum using pwelch, which takes care of segmenting the input signal. Matlab has support for MS spectrum estimation using pwelch while Octave does not.
When used for PSD estimation, pwelch.m scales the periodogram dividing it by the energy of the window:
In contrast, when estimating a MS spectrum, the periodogram should be divided by the square of the window DC value
The reason is that the window is convolved with each power spectrum peak and should be 1 to avoid modifying the peak height.
Matlab has the undocumented option of invoking pwelch.m with the argument ’ms’ for MS spectrum, such as in:
which uses the adequate scaling factor to estimate a MS spectrum.
Because ’ms’ is not supported in Octave, Listing 4.28 illustrates that a workaround is to multiply the estimated spectrum by .
1N=1024; x = transpose(10*cos(2*3/64*(0:N-1))); %generate a cosine 2Xk = (abs(fft(x,N))/N).^2; %MS spectrum: |DTFS|^2 3Fs = 2*pi; myWindow = hamming(N); %specify Fs and a Hamming window 4H = Fs*pwelch(x,myWindow,[],N,Fs,'twosided');%Welch's estimate. Third 5%parameter is [] because in Matlab is num. samples while Octave is % 6H = H * sum(myWindow.^2)/sum(myWindow)^2; %scale for MS 7plot(Xk,'x-'), hold on, plot(H,'or-') %compare
Using either Matlab or Octave, this code provides a pair of peaks of approximately 25 W for H, estimated via Welch’s method. Note that the cosine is not bin-centered and there is leakage. Matlab users14 can try a flat top window in place of Hamming’s with the command myWindow=flattopwin(N). When estimating the MS spectrum, a flat top window helps because it widens any peak in the original spectrum, such that the wider range of values has more chances of coinciding with a FFT bin. In other words, the flat top is not accurate to locate the sinusoid in frequency (bad frequency resolution) but helps when the goal is to find the sinusoid amplitude.
Another example with a sinusoid that is not bin-centered is provided below. It allows to observe the better performance of averaging segments of the signal using pwelch.m, as indicated in Listing 4.29.
1N=1000; x = 10*cos(2*pi/64*(0:N-1)); %generate a cosine 2Xk = (abs(fft(x,N))/N).^2; %MS spectrum |Xk|^2 3Fs = 2*pi; window = hamming(128); %specify Fs and window 4H=2*pi*pwelch(x,window,[],128,Fs,'twosided'); %Welch's estimate 5H = H * sum(window.^2)/sum(window)^2; %scale for MS 6disp(['Peak from pwelch = ' num2str(max(H)) ' Watts']) 7disp(['Peak when using one FFT = ' num2str(max(Xk)) ' W'])
This code informs that Xk has peaks of 15.66 W and H (estimated via pwelch.m with segments of samples) has peaks of 25.02 W (recall that the correct value is 25 W). In this and many practical cases, averaging windowed segments with pwelch.m leads to better results than using a single FFT.
Application 4.3. Speech formant frequencies via LPC analysis.
An interesting application of LPC analysis is to estimate the formant speech frequencies. The formants are related to the peaks of the spectrum of a vowel sound and are relatively well-defined in a sentence such as “We were away”, which does not have consonant sounds.
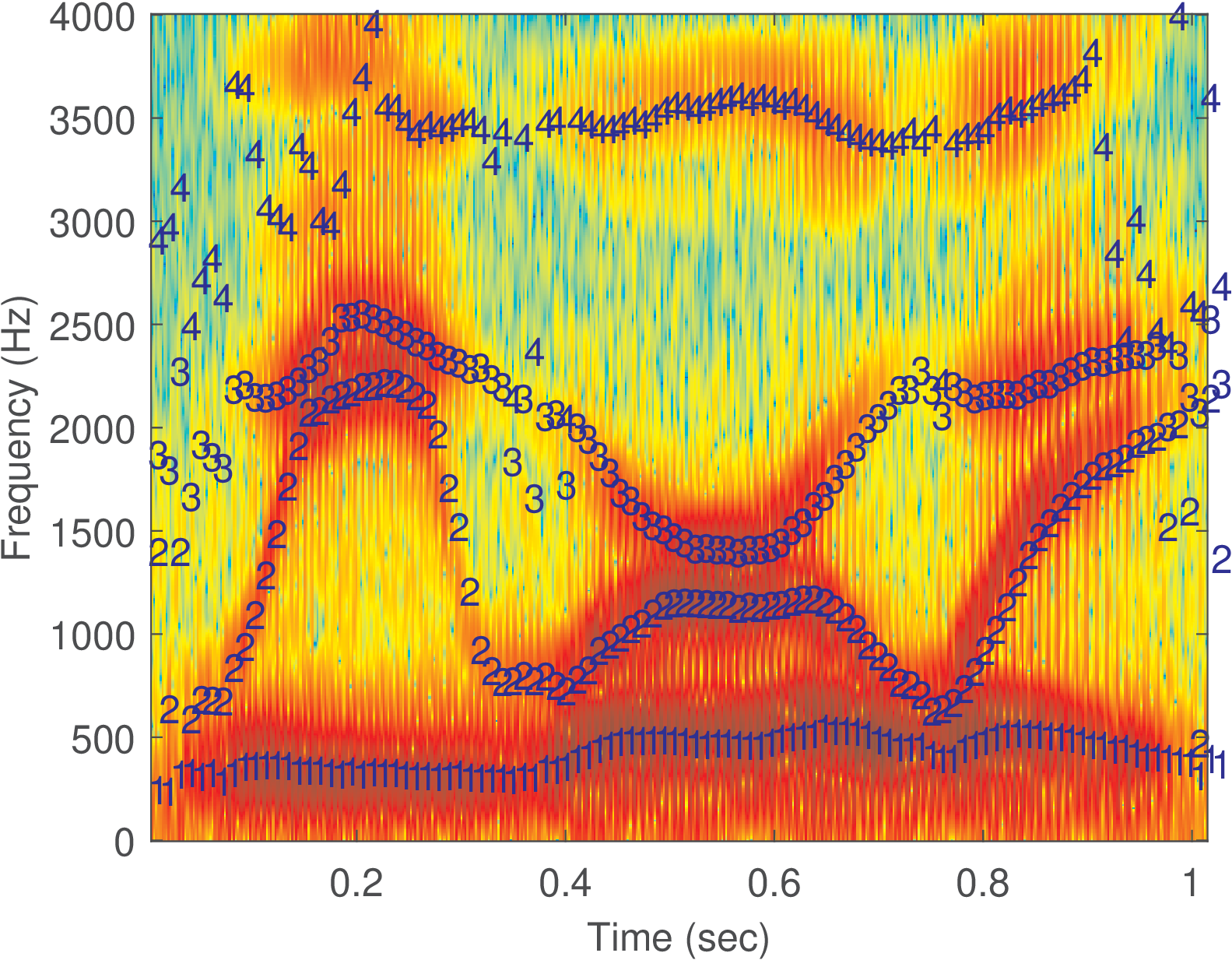
Listing 4.30 was used to obtain Figure 4.46.
1[s,Fs,numbits]=readwav('WeWereAway.wav'); %read wav file 2s = s - mean(s(:)); %extract any eventual DC level 3Nfft=1024; %number of FFT points 4N = length(s); %number of samples in signal 5frame_duration = 160; %frame duration 6step = 80; %number of samples the window is shifted 7order = 10 %LPC order 8numFormants = 4 %desired number of formants 9%calculate the number of frames in signal 10numFrames = floor((N-frame_duration) / step ) + 1 11window = hamming(frame_duration); %window for LPC analysis 12formants = zeros(numFrames,numFormants); %pre-allocate 13for i=1:numFrames %go over all frames 14 startSample=1+(i-1)*step; %first sample of frame 15 endSample=startSample + frame_duration - 1; %frame end 16 x = s(startSample:endSample); %extract frame samples 17 x = x.* window; %windowing 18 a = aryule(x,order); %LPC analysis 19 poles = roots(a); %Roots of filter 1/A(z) 20 freqsInRads = atan2(imag(poles),real(poles)); %angles 21 freqsHz = round(sort(freqsInRads*Fs/(2*pi)))'; %in Hz 22 frequencies=freqsHz(freqsHz>5); %keeps only > 5 Hz 23 formants(i,:) = frequencies(1:numFormants); %formants 24end 25window = blackman(64); %window for the spectrogram 26specgram(s,Nfft,Fs,window,round(3/4*length(window))); 27ylabel('Frequency (Hz)'); xlabel('Time (sec)'); hold on; 28t = linspace(0, N / Fs, numFrames); %abscissa 29for i=1:numFormants %plot the formants 30 text(t,formants(:,i),num2str(i),'color','blue') 31end
The code illustrates how a long signal can be segmented via windowing. It is interesting to notice that the Hamming window is typically adopted in LPC analysis, and the code uses another (Blackman) window for the spectrogram. An LPC of order 10 was used to estimate four formants. The code eliminates frequencies below 5 Hz because LPC sometimes returns real poles that correspond to a zero frequency.
Figure 4.46 indicates that at the sentence endpoints and at the pauses between words, when the vowel sounds are not well-defined, the formant estimation is noisy. In the middle of the sentence, around 0.5 s, the four formants are clearly identified. In the region around 0.2 s and also the one around 0.8 s, the estimation is problematic because more than four formants are necessary to describe the signal.
Application 4.4. LPC analysis using the autocorrelation method. Assume we want to calculate the prediction-error filter of order for the signal , as indicated in Figure 4.39.
By convention, this filter is given (in the Z-domain) as
and you can get it by solving
where is the correlation at lag .
One can note that the matrix in the above equation is symmetric and, besides, has equal elements along the diagonals. This is called a Toeplitz matrix. The matrix can be inverted with the Levinson-Durbin algorithm implemented in function ak_levinson_durbin.m. This fast algorithm has a computational cost of order instead of required by a generic matrix inversion method. The result of these two methods are compared in the code below:
1P=3; % order of LPC analysis 2x = [10, 8, 3, -2, -4, -2, 1, 2]; % example of short signal 3r = xcorr(x, P, 'biased'); % autocorrelation estimate 4r = r(P+1:end); % keep only the P+1 lags from lag=0 to P 5%% Compose matrix equation to solve via generic matrix inversion 6R=toeplitz(r(1:end-1)) % matrix with elements from R[0] to R[P-1] 7r_vector=transpose(r(2:end)) % vector with elements from R[1] to R[P] 8Atemp = inv(R)*r_vector; % matrix inversion for R*Atemp=r_vector 9A = transpose([1; -Atemp]) % follow Matlab's convention 10%% Now solve with fast Levinson & Durbin 11[A2, error, k] = ak_levinson_durbin(r, P);% our implementation 12numerical_discrepancies = A-A2 % check for errors
In a more advanced example, the code Listing 4.31 compares the results of ak_levinson_durbin.m with Matlab’s method levinson.m.
1%% Compare custom Levinson-Durbin with MATLAB's levinson() 2N = 1000; % Number of samples 3P = 3; % AR model order 4%% Generate A(z) that leads to a STABLE synthesis filter 1/A(z) 5theta = 2*pi*rand(1,floor(P/2)); %angles 6poles_half = 0.999*rand(1,floor(P/2)) .* exp(1j*theta); %poles 7poles = [poles_half, conj(poles_half)]; %complex conjugates 8if mod(P,2)==1 %add extra real pole if order is odd number 9 poles = [poles 0.8 * (2*rand-1)]; % real pole 10end 11A_true = poly(poles); % compose guaranteed real and stable 1/A(z) 12%% Generate AR process x[n] by filtering white noise 13sigma2 = 1; % driving noise variance 14w = sqrt(sigma2) * randn(1,N); % white Gaussian noise 15x = filter(1, A_true, w); % AR process (synthesis filter) 16%% Estimate autocorrelation (Matlab assumes it's real-valued) 17r = xcorr(x, P, 'biased'); % autocorrelation estimate 18r = r(P+1:end); % keep lags 0, 1, ..., P 19%% Estimate linear filter via MATLAB and custom implementation 20[A1, E1, K1] = levinson(r, P); % MATLAB reference 21[A2, E2, K2] = ak_levinson_durbin(r, P);% our implementation 22%% Compare results (result should be 0 or small number, e.g., 1e-15 23disp('Estimation errors: ||A1 - A2|| ='); disp(norm(A1 - A2)) 24disp('||K1 - K2|| ='); disp(norm(K1 - K2)) 25disp('|E1 - E2| ='); disp(abs(E1 - E2)) 26%% Show filters 27disp('True and estimated A(z):'); disp(A_true); disp(A1) %A1 = A2
The result of Listing 4.31 shows a good match of the two implementations.
Application 4.5. Spectral distortion. When the task is to compare two PSDs, the spectral distortion (SD) can be used. It is given by
|
| (4.70) |
where and are discrete-time signals and and their respective PSDs. SD is given in dB and corresponds to the root mean square value of the error between and over frequency . It should be noted that the SD can also be used to compare two MS spectra.
Because both the PSD and MS spectrum are normalized versions of the squared magnitude of a DTFT and the SD divides two spectra, any normalization factor is canceled out in Eq. (4.70). Therefore, Eq. (4.70) can be written in terms of DTFTs as
where and are the respective DTFTs.
Eq. (4.72) can be approximated by
|
| (4.73) |
where and are the respective -point FFTs. Listing 4.32 illustrates a software routine to calculate SD.
1function distortion = ak_spectralDistortion(x,y,Nfft,thresholdIndB) 2% function distortion = ak_spectralDistortion(x,y,Nfft,thresholdIndB) 3%Returns the spectral distortion (SD) in dB as defined at 4% http://en.wikipedia.org/wiki/Log-spectral_distance 5X=abs(fft(x,Nfft)); %Calculate magnitude values of DTFTs 6Y=abs(fft(y,Nfft)); 7logX=20*log10(X); %Convert to dB and use factor=20 to convert ... 8logY=20*log10(Y); %DTFTs into power spectra using log(X^2)=2*log(X) 9maximumValue = max([max(logX) max(logY)]); %Avoid numerical problems 10minimumValue = maximumValue - thresholdIndB; %such as log of 0 11logX(logX<minimumValue)=minimumValue; %Impose the floor value 12logY(logY<minimumValue)=minimumValue; 13distortion = sqrt(mean((logX-logY).^2)); % SD as a mean-squared error
One issue when using logarithms is to deal with argument values equal to zero. For example, in Matlab/Octave, log(0) gives -Inf and can lead to NaN after operations such as 0*log(0). To avoid numerical problems, Listing 4.32 uses a floor value based on a threshold to limit the minimum value of an argument for logarithm functions. Some lines of Listing 4.32 that are not being shown also deal with special situations and are an example of how to prevent problems via proper exception treatment when using software. For example, some lines of Listing 4.32 deal with the situation where both signals and have only zero values.
Application 4.6. Spectral distortion of speech autoregressive models. In speech coding applications, the signal is segmented into frames. Given two speech signals, it is discussed here how to compare their spectra using AR models in a frame-by-frame basis. While Application 4.5 used one value of SD for the whole duration of the signals, here the SD is calculated for each frame.
The pair of signals can be found at folder Applications/SpeechAnalysis. One of the files correspond to the digit “eight” spoken by a male speaker. The other file was generated by a computer (more specifically, using the Klatt speech synthesizer) and aims at sounding indistinguishable from the first, or target speech.
Listing 4.33 shows a code snippet with the part that segments the signals into frames and calculates the SD as described in Listing 4.32 and also two other SD versions. These SD versions are comparisons between autoregressive models and are calculated with the function ak_ARSpectralDistortion.m. Listing 4.33 uses the array isNotSilence, which was obtained from function Applications/SpeechAnalysis/endpointsDetector.m, to avoid computing the SD values for frames that have a low power and can be considered as silence, not speech.
26for i=1:M %do not use last frame, because it may use zero padding 27 if isNotSilence(i)==0 28 continue; %skip because this is a silence frame 29 end 30 firstSample = 1+(i-1)*S; 31 lastSample = firstSample + L - 1; 32 x=target(firstSample:lastSample); %frame from target signal 33 y=synthetic(firstSample:lastSample); %frame from the other signal 34 sd_all(i)=ak_spectralDistortion(x,y); 35 sdAR_all(i)=ak_ARSpectralDistortion(x,y,10,Nfft); 36 sdARp_all(i)=ak_ARSpectralDistortion(x,y,10,Nfft,60,1); 37 disp(['#' num2str(i) ': SD=' num2str(sd_all(i)) ', AR SD=' ... 38 num2str(sdAR_all(i)) ' and AR SD (power)= ' ... 39 num2str(sdARp_all(i))]); 40end
Autoregressive models are widely used in speech coding applications and their quantization is often evaluated according to the AR version of the SD. In this context, transparent quantization is obtained when the average SD is not larger than 1 dB, having no outliers with SD larger than 4 dB and at most 2% of frames with SD between 2 and 4 dB.