B.3 Probability Concepts for Signal Processing
This appendix provides a brief overview of probability concepts relevant to digital signal processing.
B.3.1 Joint and Conditional Probability
Let and be two events. Their joint probability, denoted by (or equivalently ), quantifies the probability that both events occur.
The conditional probability of given is defined as
Equivalently, the joint probability can be written as
Two events and are said to be independent if
which implies that
Example B.1. Fair coin. Consider two independent tosses of a fair coin. Let be the event “the first toss results in heads” and the event “the second toss results in heads.” Then , and
Moreover, , reflecting the independence of the two events.
Starting from the two equivalent factorizations of the joint probability,
we obtain
|
| (B.25) |
which is known as Bayes’ rule (see, e. g., [ urlBMpro]).
Although the notation may suggest that influences , conditional probability does not, in general, imply a causal relationship.
B.3.2 Random variables
Understanding the application of probability concepts into signal processing requires distinguishing three concepts: experiment outcomes, events, and random variables. A random variable maps outcomes into numbers as detailed below.
The outcome of a probabilistic experiment is not necessarily a number, but an element of a set , called the sample space. For example, when tossing a coin, the outcome can be or .
A random variable provides a way to assign numerical values to these outcomes. Formally, a random variable is a function
which associates a real number with each outcome . (More generally, random variables may take values in , vectors, etc., but here we restrict attention to real-valued variables.)
A common source of confusion is the notation. In standard mathematical notation, a function is written as , where is the function and is its output. In probability, however, it is customary to use the same symbol both for the function (the random variable) and for its values. Strictly speaking, the numerical value is , but in practice we often write simply . This is an abuse of notation that must be understood from context.
Every random variable induces a probability distribution on the real line. If the set of possible values of is finite or countable, is called a discrete random variable and is described by a probability mass function. If takes values in a continuum, it is called a continuous random variable and is described (when it exists) by a probability density function.
In summary, a random variable is a function and its “randomness” comes from the randomness of its input , not from the function itself.
First note that the outcome of a probabilistic experiment need not be a number but any element of a set of possible outcomes. For example, the outcome when a coin is tossed can be “heads” or “tails”. Basically, random variables allow us to map any probabilistic event into numbers, which are then conveniently manipulated using mathematical operations such as integral and derivatives. A source of confusion is that, strictly, a random variable (e.g., or ) is a function. More specifically, a random variable (r.v.) is a function that associates a unique numerical value with every outcome of an experiment (r.v. can be complex numbers, vectors, etc., but here it will be assumed as a real number). In math, a function output is often represented as . When dealing with a r.v., instead of adopting something like , both the random variable (equivalent to the function ) and its output value (equivalent to ) is represented by a single letter (e.g., or ).
There are two types of r.v.: discrete and continuous. Hence, a r.v. has either an associated probability distribution (discrete r.v.) or probability density function (continuous r.v.).
Assume a discrete r.v. and a continuous r.v. . While the former is typically described by a probability mass function (pmf), the latter can be described by a probability density function (pdf).
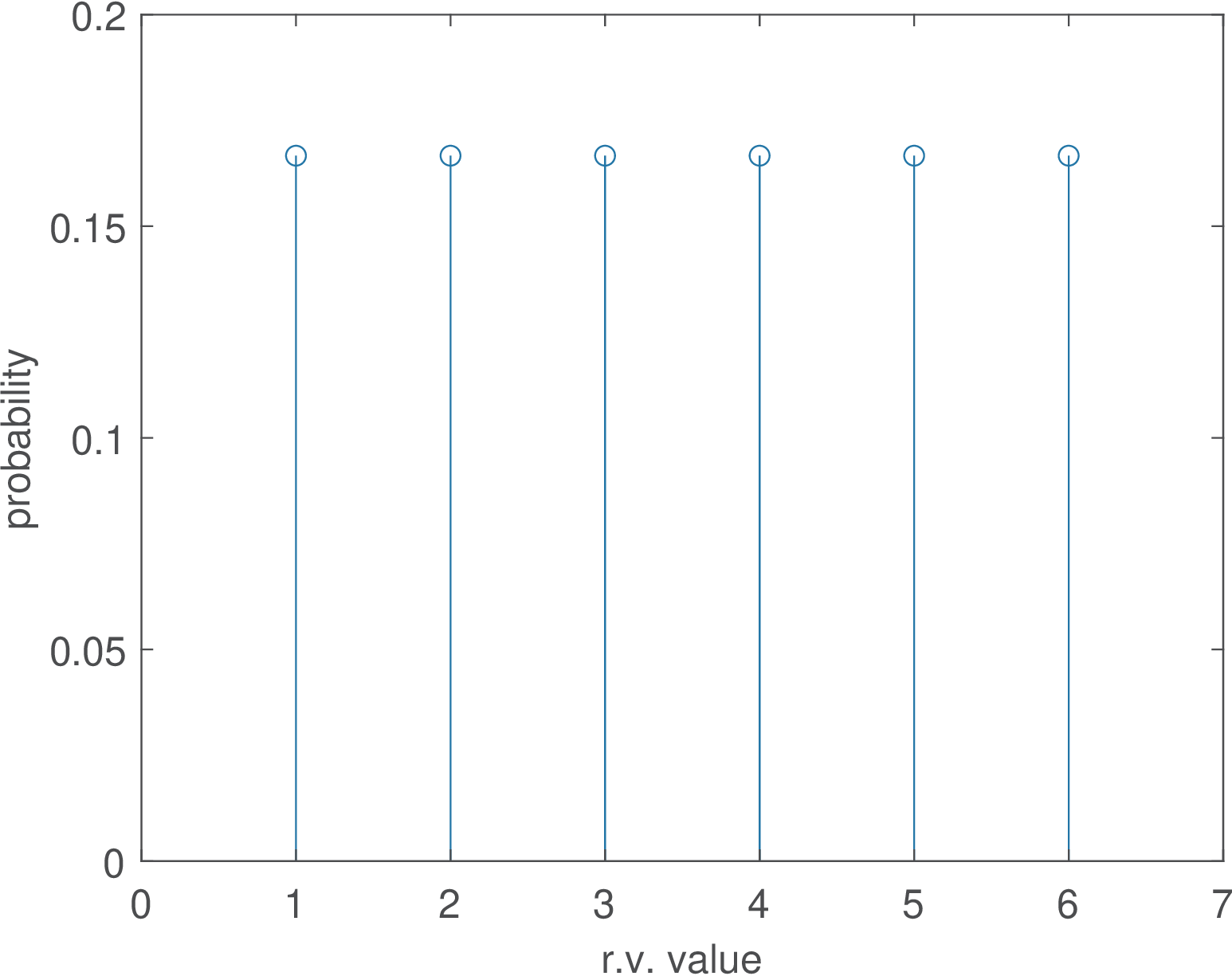
Say that represents the outcome of rolling a dice. Its PMF is shown in Figure B.1 and indicates that each face of a fair dice has a probability of .
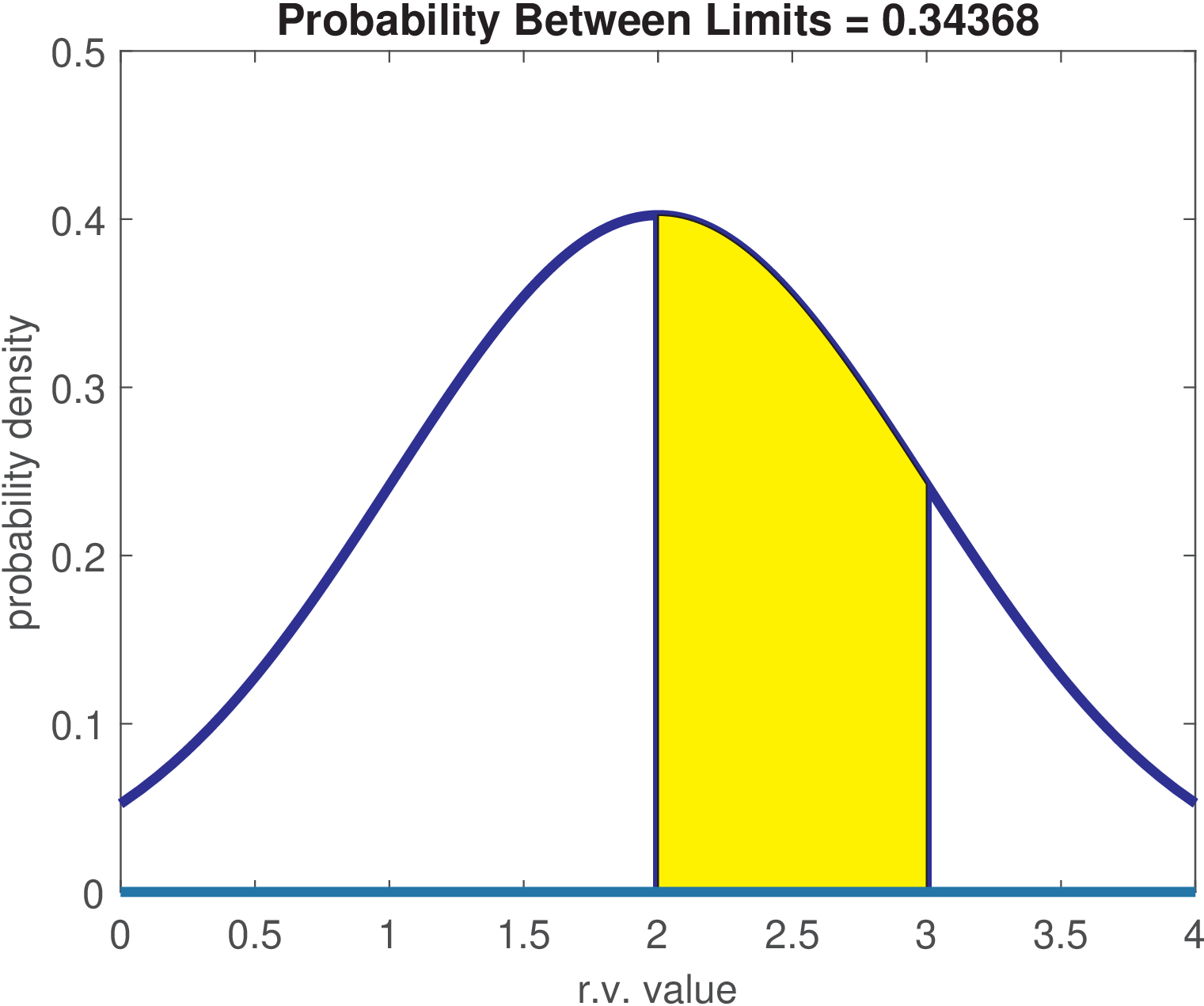
Now consider that represents the amplitude of a Gaussian noise source with mean 2 and variance equal to 1. Its pdf is shown in Figure B.2. A common mistake is to assign a non-zero value to a specific value of a density function. For example, it is wrong to say that the probability of is , in spite of this being the value of the function. The function represents a density, and the correct answer is that the probability of , or any other point, is 0. One can extract probability from a pdf only integrating it over a non-zero range of its abscissa. For example, over the range [2, 3] the probability is approximately 0.34 as indicated by the shaded area in Figure B.2.
When dealing with ratios of pdfs it is possible to have the abscissa range canceling out. For example, if a discrete binary r.v. is used to represent two classes (A and B, for example), and each class has a pdf associated to it ( and , respectively), the Bayes’ rule states
|
| (B.26) |
In this case, cancels because it appears on both numerator and denominator.
B.3.3 Expected value
The expected value operator is the most common mathematical formalism for calculating an average (or mean).
The expected value is a linear operator (see Appendix B.7.1 for more information about linearity), such that
|
| (B.27) |
The expected value of a random variable can be estimated as a typical average when can be represented by a finite-dimension vector. For example, if is a vector with random samples from , the expected value can be estimated as , where is the conventional mean value.
If one has realizations of a random variable , for instance organized as a vector , and is looking for the expected value of a function , it is possible to apply the function to each realization (value of ) and then take their average. For example, assume and one is interested on estimating based on realizations of . In this case, applying to elements of leads to the vector , which has the average . The estimate is .
As another example, consider is known (or has been previously estimated), and one is interested on estimating the variance . In this case, and if the realizations are still , which has an average , applying leads to a vector with mean value . In this case the estimated variance is .
The variance is often denoted as , and can be written as
which is often interpreted as .
When a discrete random variable has distinct values, its mean can be estimated with
|
| (B.29) |
where is the probability of the -th possible value . For instance, the realizations have only distinct values: and , each one with estimated probability . Hence,
The same result could be obtained by directly taking the mean value of the elements with
Note that corresponds to the -th element in , while is the -th distinct value of .
When is a continuous random variable, instead of Eq. (B.29) one has its continuous version:
where is the probability density function of . In this case, for each value of , the role of the probability in the discrete r.v. case, is played by the value that corresponds to a “weight” that depends on the likelihood of the specific value .
In order to find for a given function one can use:
|
| (B.30) |
B.3.4 Orthogonal versus uncorrelated
Two random variables and are said to be orthogonal to each other if
They are said to be uncorrelated with each other if
The above condition is equivalent to
Note that if one or both of and have zero mean, then the orthogonal and uncorrelated conditions are equivalent.
B.3.5 PDF of a sum of two independent random variables
If and are independent random variables and , then the probability density function (pdf) of is given by the convolution
Example B.2. Probability distribution of noisy bipolar signal. As an example, consider a bipolar signal that takes values V with equal probability, whose pdf is
and additive white Gaussian noise (AWGN) with pdf . In this case, the pdf of is obtained by convolution and results in two shifted replicas of :
That is, the output pdf consists of two Gaussian components, each scaled by and centered at and , respectively.